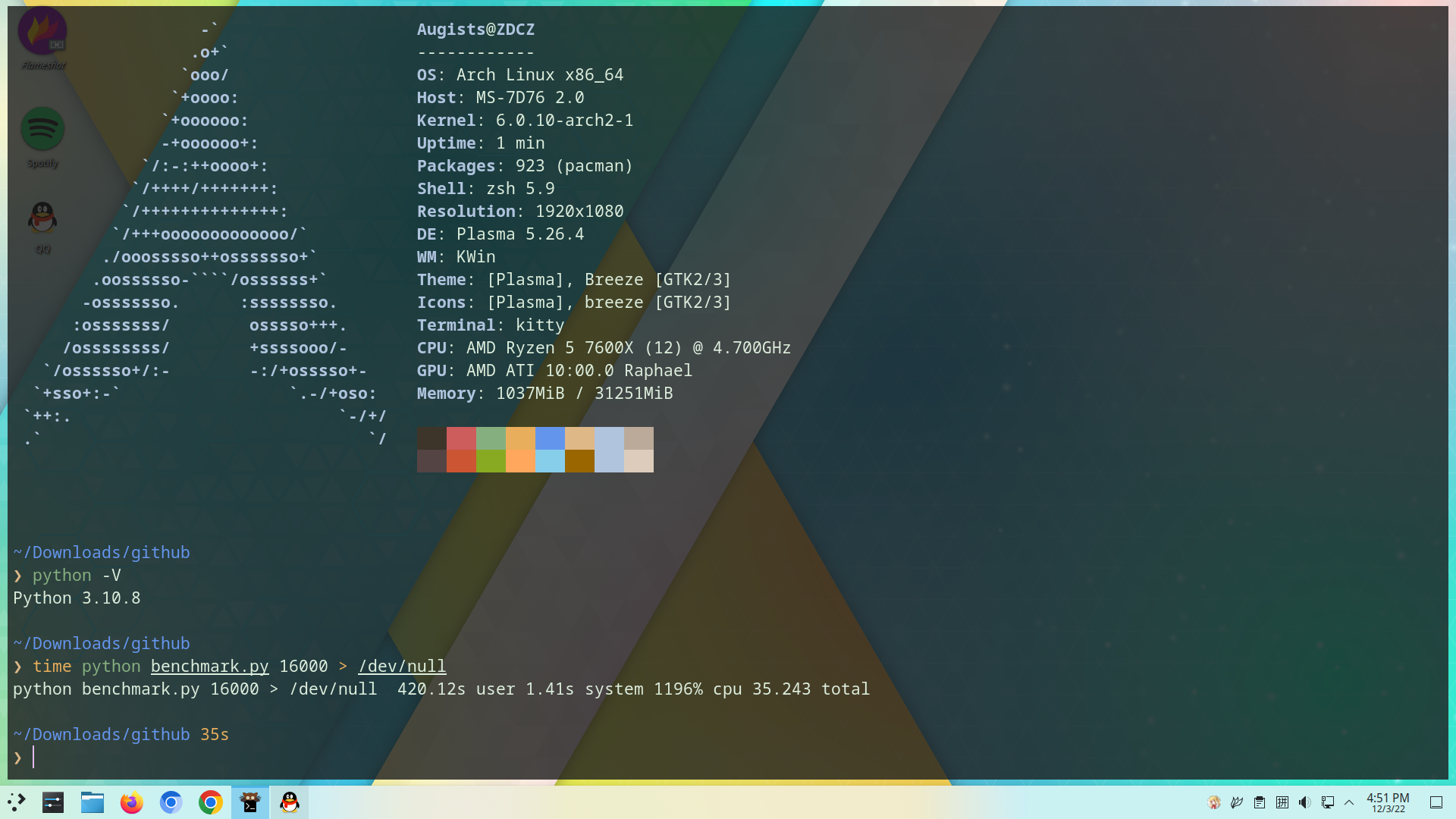
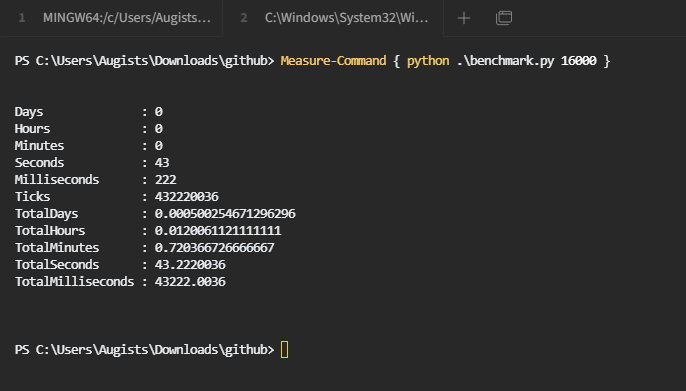
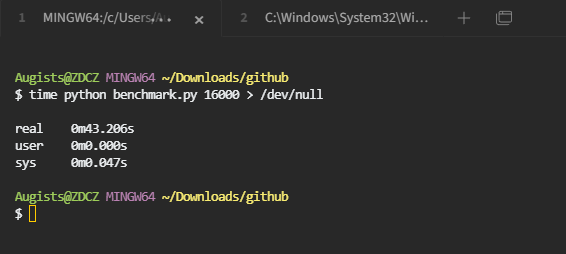
当然,这是一个非常不严谨的测试,如果我没有记错的话,当时的 Windows 装在致钛盘,Linux 装在铠侠,并且由于系统不同,也没有条件使用相同的终端模拟器,Kitty 可能还会调用核显进行加速等等 跑这个 benchmark 也仅仅是为了娱乐,并不意味着相同的工作在 Windows 上的处理效率就一定比在 Linux 上要低
# The Computer Language Benchmarks Game # https://salsa.debian.org/benchmarksgame-team/benchmarksgame/ # # contributed by Joerg Baumann
from contextlib import closing from itertools import islice from os import cpu_count from sys import argv, stdout
defpixels(y, n, abs): range7 = bytearray(range(7)) pixel_bits = bytearray(128 >> pos for pos in range(8)) c1 = 2. / float(n) c0 = -1.5 + 1j * y * c1 - 1j x = 0 whileTrue: pixel = 0 c = x * c1 + c0 for pixel_bit in pixel_bits: z = c for _ in range7: for _ in range7: z = z * z + c if abs(z) >= 2.: break else: pixel += pixel_bit c += c1 yield pixel x += 8
defcompute_row(p): y, n = p
result = bytearray(islice(pixels(y, n, abs), (n + 7) // 8)) result[-1] &= 0xff << (8 - n % 8) return y, result
defordered_rows(rows, n): order = [None] * n i = 0 j = n while i < len(order): if j > 0: row = next(rows) order[row[0]] = row j -= 1
if order[i]: yield order[i] order[i] = None i += 1
defcompute_rows(n, f): row_jobs = ((y, n) for y in range(n))
if cpu_count() < 2: yieldfrom map(f, row_jobs) else: from multiprocessing import Pool with Pool() as pool: unordered_rows = pool.imap_unordered(f, row_jobs) yieldfrom ordered_rows(unordered_rows, n)
defmandelbrot(n): write = stdout.buffer.write
with closing(compute_rows(n, compute_row)) as rows: write("P4\n{0} {0}\n".format(n).encode()) for row in rows: write(row[1])
if __name__ == '__main__': mandelbrot(int(argv[1]))