Load Balance Algorithm Analysis (What is the fair in lb?)
Load Balance Algorithms
写在最前:LB 算法的更新是一直在考虑如何才算是公平性的问题。它想讨论的是在不同层面(角度)的公平性和不同场景下的公平性。我们会需要从不同的角度看待问题:client 要看自己能不能及时访问到服务、LB 要看自己怎么分配、RS 要一直有能力能及时处理。服务中会面临各种差异:RS 之间性能有差异、当前已有的连接不一样、甚至有的实现里 LB 集群内也会有差异。要考虑不同的场景:业务不是固定不变的、LB 也可能根据需要扩容、有的厂商的实现里还需要考虑跨地域等等问题
应该说 LB 算法之间没有绝对的好坏之分,而是根据场景需求选择最合适的方法
比较好的方式是评估哪台服务器有能力继续及时的处理请求,我们可以通过一些方式或指标来评判谁当前更有能力或更能及时的进行处理,将下一个新连接交给它。怎么判断谁现在更有能力或更能及时处理呢?
- 当前 CPU 负载
- 已有的连接数量
- 网络连接空闲
- [发散] 服务器主动提出想要接收 (或任务窃取)
基础公平(雨露均沾)
- RR (Round Robin,轮询)
最简单来讲,不考虑任何可能的差异,我们只需要轮询的转发给所有的后端服务器即可,保证每个服务器雨露均沾。就像下面的调度结果一样,所有 RS 都会按顺序排队拿到下一个新连接。这保证了最基础的调度公平
但是事实上,这没有考虑过 RS 之间本身会存在性能差异,也没有动态去感知当前的状态差异
Real Server: A | B | C
| i | 0 | 1 | 2 | 3 | 4 | 5 | … |
|---|---|---|---|---|---|---|---|
| select | A | B | C | A | B | C | … |
从服务器间存在差异的角度
所以我们要开始考虑RS之间的差异
相比于收集 RS 还有多少任务要处理,或是持续统计所有 RS 的 CPU 占用率这样的方式,肯定是直接由 RS 性能来定义权重最为简单高效
权重是需要动态可调的。对业务来说,新上线的 RS 可以自行动态的由低到高的缓慢修改其权重来实现预热等一些需求,或是新增 RS 的权重相应拉高来保证它在开始时有更多的任务去处理来快速分担其他 RS 的压力等
(I)WRR
对每个 RS 都相应的配置其权重,优先选择当前权重最高的 RS 进行调度
- WRR (Weighted Round Robin,加权轮询)
传统的 WRR 是以队列的层面看待,相当于为每个 RS 开辟一个发送队列,批量的将与权重数量相当的包直接转发给选择的 RS。它的好处也是可以批量处理,但是这对 LB 来说没有必要。LB 是以连接的层面看待问题,我们只考虑新连接的调度,已有调度的连接会继续向之前记录的转发
简单的改进是以单个数据包的层面进行划分。对每个数据包来说选择当前权重最大的 RS 进行转发并更新其当前权重
- IWRR (Interleaved WRR,交错的加权轮询)
IWRR 尽量强调了轮询的处理,保证调度初期是以轮询的方式选择,直到其当前权重到 0 就直接跳过
下面是 LVS 中的 WRR 实现,它可以看作是反向的 IWRR(先保证权重差异,后轮询)
i 初始化 -1 开始遍历,每一整轮获取最大权重作为阈值,每一小轮减掉最大公约数,最后向大于阈值的 RS 转发
while (true) {
i = (i + 1) mod n; // i: initialized with -1
if (i == 0) {
cw = cw - gcd(S); // cw: current weight
if (cw <= 0) {
cw = max(S); // max: get the maximum weight of all servers
if (cw == 0)
return NULL;
}
}
if (W(Si) >= cw)
return Si;
}**问题:**权重差
- WRR 的权重配置中如果出现相差较多的权重差,就会导致某一段时间里做出连续相同的调度选择。这对 LB 来说是比较致命的,从 RS 的角度考虑,这一台较高会在短时间内打入大量的新连接 -> 平滑处理,打散高权重的连续调度
- 一整轮调度中间的权重更新会导致重新开始的调度,从更长的时间线上看会加剧连续调度的问题 -> 权重延迟更新,只更新 RS 权重但不修改当前权重值,会使得新权重在下一轮才会被感知到(也可以把延迟更新看作优势)
SWRR
- SWRR (Smooth Weighted Round Robin,平滑加权轮询)
为了能打散高权重的连续调度,Nginx 提出了 SWRR,希望能把连续调度尽可能平滑的插入到别的位置里
在SWRR中需要所有服务器的配置权重,并维护每一个服务器当前的权重和所有服务器的总权重
对于每一次选择:
- 选择当前权重最高的 RS 调度
- 选择的 RS 当前权重减去总权重,加速抹平权重间的差值
- 为了保证当权权重之和仍然等于总权重,为每个 RS 的当前权重增加其定义的权重
这里我们以三台服务器为例,权重分别为 2, 2, 6。它们的总权重是10,GCD是2
它在WRR调度中的顺序是 C C A B C
SWRR的平滑调度顺序计算过程如下,表格记录的是 current_weight:
一开始每台服务器的当前权重都初始化为定义的权重,然后选择了最大的C服务器
| A | B | C |
|---|---|---|
| 2 | 2 | 6 |
然后将C服务器的当前权重减掉总权重10,得到-4
| A | B | C |
|---|---|---|
| 2 | 2 | -4 |
然后更新所有服务器的当前权重,在之前的基础上增加定义的权重。继续下一次选择,这里A和B都是最大权重,由于没有引入随机性,我们选择了更靠前的A
| A | B | C |
|---|---|---|
| 4 | 4 | 2 |
选出来的服务器继续减掉总权重10
| A | B | C |
|---|---|---|
| -6 | 4 | 2 |
再更新所有服务器,再选择最大
| A | B | C |
|---|---|---|
| -4 | 6 | 8 |
| -4 | 6 | -2 |
| -2 | 8 | 4 |
| -2 | -2 | 4 |
| 0 | 0 | 10 |
| 0 | 0 | 0 |
最终所有服务器的当前权重回到初始状态,进入下一整轮
最终的 SWRR 调度顺序是 C A C B C
可以看到相比WRR调度,连续的C中间被插进去了一次A
SWRR的核心逻辑是:规律的调整权重但永远保持总权重不变。它已经能很好的打散我们在一整轮调度中的连续调度结果
**问题:**调度时间开销和相同调度选择
- 每次调度需要遍历所有的 RS 找到当前权重最大的一个,查找调度时间开销为 O(N) 或 O(logN)(如果选择用例如最小堆维护,就需要额外花时间维护堆),更新当前权重 O(N) -> 预先计算调度顺序,调度时可以直接 O(1) 选择
- 集群中每一个单机和单机中每一个 WORKER 都会做出相同的调度选择,使得从整体上来看(或从 RS 的角度看)LB 会做出多次连续重复的调度 -> 调度顺序随机初始位置
- 其他优化方案参见 Nginx 章节
VNSWRR
针对前面两条SWRR的问题,阿里提出了利用虚拟节点的SWRR,但是这个虚拟节点和后面一致性哈希的虚拟节点不是同一个意思
- VNSWRR (Virtual Node Smooth Weighted Round Robin,虚拟节点平滑加权轮询)
对于 SWRR,预先计算好完整的调度顺序表,并在一开始选择随机的 idx 开始调度,从而打散刚启动时集群整体的连续相同调度
表中的第一行的结果就是我们前面SWRR的调度顺序,通过预先计算,在调度时我们就可以O(1)的查找到这一次的调度结果
每一行代表一台LB单机,假设它5台机器随机的起点都不一样,那么对整个集群来说的调度顺序可能就是在这里走S型的散乱顺序了
LB(5), SWRR: C A C B C
| LB id | random idx | select | select | select | select | select |
|---|---|---|---|---|---|---|
| 0 | 0 | C | A | C | B | C |
| 1 | 1 | A | C | B | C | C |
| 2 | 2 | C | B | C | C | A |
| 3 | 3 | B | C | C | A | C |
| 4 | 4 | C | C | A | C | B |
这里放了从整体角度看的SWRR和VNSWRR可能的实际调度顺序,可以看到SWRR仍然会有连续的调度结果。如果在过程中还会发生权重变更,那这个连续的调度可能会更夸张
从整体的角度看
SWRR: C C C C C A A A A A C C C C C B B B B B C C C C C
VNSWRR: C A C B C A C B C C C B C C A B C C A C C C A C B
但是,回来看VNSWRR算法的思想,它需要预先计算好调度顺序表。这也就意味着,我们在预先计算的过程中是不能开始调度的,且每次发生权重修改或是后端服务器扩缩容都需要重新计算这个调度顺序表
GCD 优化
调度顺序表的长度取决于总权重,但实际上会以所有 RS 权重的最小公倍数为一轮(实际上权重本来就可以除最大公约数进行约分,等效权重),所以只需要存放 GCD 后的总权重长度
| weight | A | B | C |
|---|---|---|---|
| before | 2 | 2 | 6 |
| after | 1 | 1 | 3 |
在这里就是从10缩小到5,这个比较好理解
Step + Unordered List 优化
预先计算完整的调度顺序表在 RS 数量较多的时候会消耗较长的时间,而这段时间被认为是无法开始调度的
我在这里放了它的计算和调度两部分的伪代码。上面是调度顺序表的计算,它在拿到下一个SWRR的结果之后就会把它放进vrs table里。下面实际调度的时候,只需要顺序的遍历vrs table表就可以得到调度顺序
N: RS number, M: total weight after dividing GCD
M <- count total weight # O(N)
malloc vrs_table with M
for every loop idx(auto increment) in M: # O(M)
find RS a with max effective weight # O(N)
RS a effective weight update # O(1)
update all RS effective weight # O(N)
vrs_table[idx] = RS arandom start index i
for every schedule:
RS a = vrs_table[i] # O(1)
i = (i + 1) % M
# make sure RS a alived
while RS a is not alived:
RS a = vrs_table[i]
i = (i + 1) % M
return RS a可以看到在计算调度顺序表的循环里,idx只是用来表示在表中下一个记录的位置,和实际的调度计算无关。这也就意味着它是可以随时暂停的
所以在计算时,我们可以给它划分步长Step,后面的部分以后再来计算。这样表长度M就被分成了M/Step次分开算,只要算完当前Step内的结果就可以开始调度了
通过分 Step 计算来压缩一开始计算调度顺序表的时间,直到后续调度需要时再计算下一个 Step 的调度顺序,直到计算完完整的调度顺序表。但是这就导致随机 idx 只能在一个 Step 的范围内选择
打乱 RS 列表顺序,使相同权重的 RS 在计算调度顺序时会有更为随机的选择,从而使得在 Step 内的 idx 随机扩大到 Step 结尾的相同权重部分(由于 RS 权重配置中及 VNSWRR 调度顺序计算的过程中相同权重的出现很正常,随机范围扩大)
Step 步长大小选择
实验统计结果确定
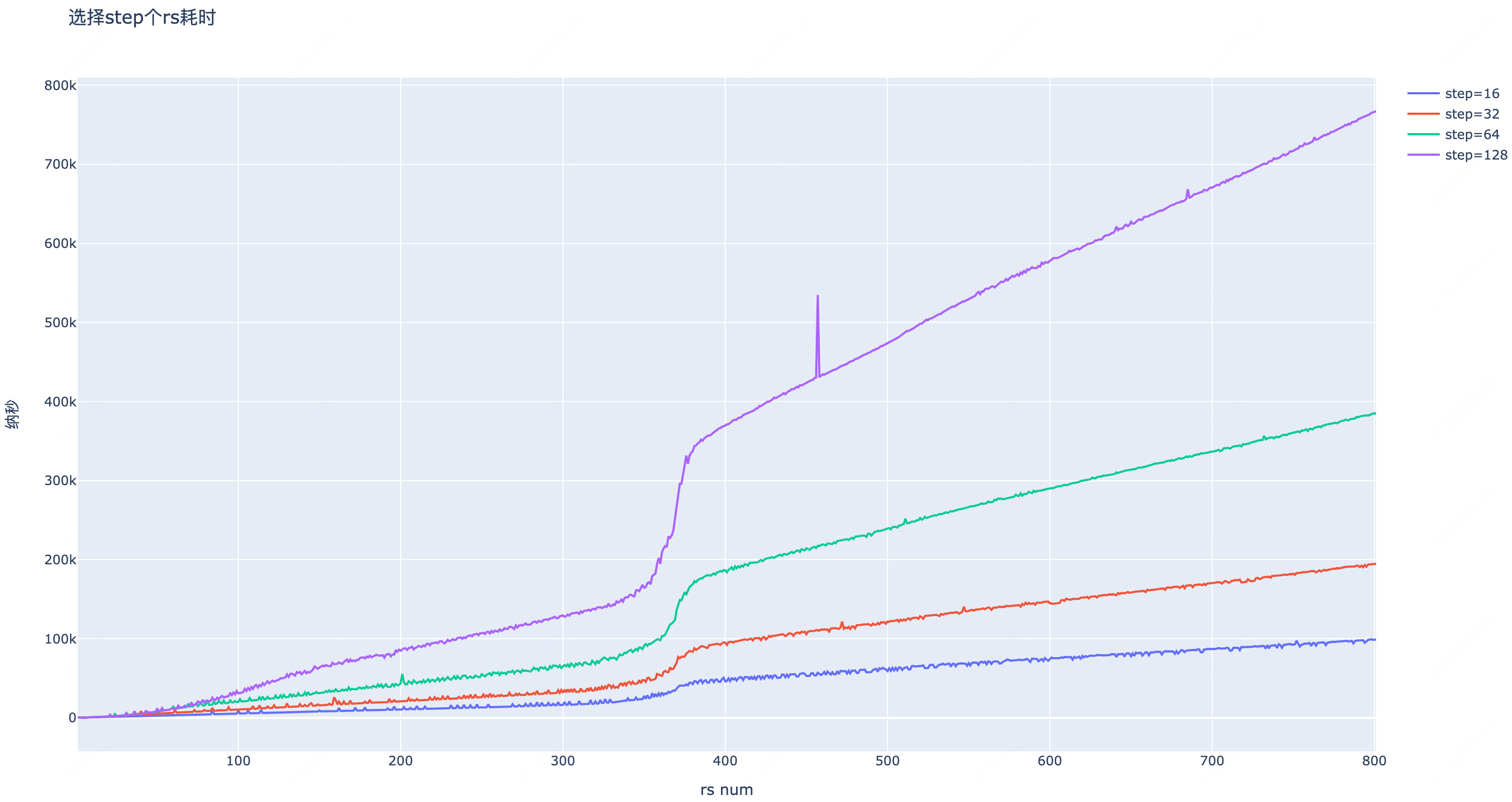
通过实验可以看到,不同的Step都会随着RS数量增加而花费更多时间,这也和我们前面Step和RS数量N成反比的结论基本一致。我们在100k纳秒位置画一条线,意思是控制每个Step的计算时间在这个时间以内,这样保证表计算对调度的时间影响较低。最终得到了下边的结果
| rs num | step |
|---|---|
| <= 200 | 128 |
| <= 300 | 64 |
| <= 400 | 32 |
| more | 16 |
但是随之而来的又有一个问题:原来计算完整调度表的时候可以随便定一个起始位置,现在只计算一个Step了,我们也没法从没计算的部分开始。现在的解决方案是打乱RS链表的顺序,这样在SWRR计算过程中面对相同权重进行选择时,就会有不同的选择结果,从而扩大了随机范围
除了本身就能打乱一些调度顺序,在关键节点Step的位置,如果有(大概率)很多个相同当前权重的结果,就意味着随机范围扩大到了红色箭头的右端点的位置
事实上因为中间也会有多个相同权重做选择的场景,打乱RS顺序的影响还会更大
**问题:**分步计算、权重更新和乱序算法
- 分布计算会在前几次调度时计算下一个 Step 的调度顺序表 -> 改为 next_idx 快到 next_init_idx 时再计算下一个 Step,打散调度顺序的计算
- 每次有 RS 的权重更新都会导致调度顺序表需要重新计算。如果有频繁的权重更新,会使得调度顺序表的计算开销被放大 -> 问题1的解决方案能部分保证不会连续的计算 Step 内调度顺序 + 调度顺序的计算现在第一个 Step 放在 CTRL 线程,后续 Step 计算在 WORKER 线程调度时。因读写锁保护范围较大而与 WORKER 的调度互斥,改为由 CTRL 线程开辟新内存进行完整调度顺序表的计算,然后直接替换表指针来减小互斥时长,使调度受到表更新的影响减小:先继续用旧的调度顺序表来做调度选择,指针替换后再使用新的调度顺序表,不会因 WORKER 需要计算而阻塞调度
- 当前的乱序算法是将所有 RS 以随机顺序挨个添加到新的临时链表里,O(N^2) -> 参考洗牌算法,BV1tNKfz1Eqc
- 每张牌给随机值,按照随机值排序,时间 O(NlogN),空间 O(N) 但可以和 Maglev 一致性哈希共用偏好数组
- 新版 Fisher-Yates 算法:依赖数组 O(1) 取值。维护牌堆数组的洗好和未洗两部分,每次将未洗的最后一张牌 last_idx 与随机未洗位置 random_idx (0 ~ last_idx) 的牌 O(1) 交换,并将最后一张 last_idx 当作洗好的部分。最终可以 O(N) 时间随机洗牌 -> 需要额外存储一个 RS 数组用来取 random_idx
random start index i in (0, Step)
next init idx j = Step
for every schedule:
if j < M:
calculate next Step
j += Step
RS a = vrs_table[i] # O(1)
i = (i + 1) % M
# make sure RS a alived
while RS a is not alived:
RS a = vrs_table[i]
i = (i + 1) % M
return RS a改为 next_idx 快到 next_init_idx 时再计算下一个 Step,打散调度顺序的计算
因为我们做分步计算存储了额外的 next_init_idx 指针,实际上可以改为在当前已经计算完的调度顺序表用完的时候再去计算下一个Step的结果,这样再加上我们一开始随机的起点位置,能更好的打散调度顺序计算的影响。并且考虑到可能会有的变化导致的重新计算,这也能尽量少的进行无效的调度顺序计算
random start index i in (0, Step)
next init idx j = Step
for every schedule:
if j == i:
calculate next Step
j += Step
RS a = vrs_table[i] # O(1)
i = (i + 1) % M
# make sure RS a alived
while RS a is not alived:
RS a = vrs_table[i]
i = (i + 1) % M
return RS a首先,在我们当前的实现里,会在前几次调度时查看并计算还未计算的 Step。这其实会影响前几次调度的延迟,等于前几次调度的时候把整个调度顺序表计算出来,相比不划分 Step 的完整计算区别不大,甚至还把原本 CTRL 的计算开销放到了 WORKER 里。但是在实际线上的场景里,LB 需要维护大量的 svc 并处理他们自己的新连接,几乎没有可能会在同一个 WORKER 的批处理里面遇到同一个 svc 的多个新连接的场景,所以问题一的优化意义不大,在实际线上不可能被感知到
需要注意的是,全局使用一个调度顺序表是不可行的。目前实现里为了更高的 cache 命中率等原因,所有 svc rs 的记录都是 per WORKER 的模式。同样在调度顺序表这里也需要使用 per WORKER 的单独计算,而非 global 表并由 WORKER 自己维护本地的随机 idx。但是,如果表顺序一致,CTRL 计算一次并直接复制给每一个 WORKER 是可行的
这其实所有预先计算的方式的通病。只要修改了权重或者说有 SVC RS 更新就需要重新计算调度顺序表
然后是乱序算法。这里只考虑打乱RS顺序的问题。在当前的实现里,需要以随机顺序添加到新的临时链表中,时间O(N^2)
我偶然间在b站上看到了一个介绍洗牌算法的视频,顾名思义洗牌算法就是想解决二维的乱序问题
第一种方案是随机值排序,时间可以压缩到 O(NlogN),但我们就需要额外的空间来记录随机值结果
第二个是 Fisher-Yates 算法,图中蓝色代表完整的RS列表,红色代表以乱序的部分。从右向左遍历,将当前位置的RS与前面随机位置的RS交换,然后添加到已乱序部分。这显然依赖数组的O(1)存储,但最终能实现O(N)时间的打乱顺序
从数据包间存在长短差异的角度
数据包之间会有长短(尽管这在 LB 认为是一致的),它可能影响的更多是收发包的时间开销(假设 RS 正在大量收包甚至接近超过处理能力范围,RS 的收包成为瓶颈。因为 LB 不需要考虑这种情况,所以只做简单介绍)
参考上一章的权重分配(传统WRR 算法),这里将数据包的大小作为权重的影响因素。刚发送了长数据包的 RS 不应成为下一次的选择
DWRR
- DWRR (Deflicit Weighted Round Robin,赤字轮询)
赤字计数器表示此轮可以发送的最大字节数,如果其大于等于数据包大小则此轮可以发送(并将计数器减掉数据包大小),否则放到下一轮考虑。赤字计数器每轮均等增加或按照权重配置增加。对应到 LB 是为所有 RS 维护赤字计数器,每轮增加权重值,并选择下一个计数器值大于数据包大小的 RS 调度
不同的 WRR 算法对比
| Algorithm Compare | ||
|---|---|---|
| (I)WRR (Packet number level) | 循环调度的周期短 (RR IWRR) 实现简单,不需要维护太多信息 可以让权重延迟更新,不需要立刻响应权重变化 | 大报文获得的实际带宽要大于小报文 权重差值较大会导致最后大量新连接连续打到同一个 RS |
| DWRR (Bandwidth level) | 考虑报文长度带来的带宽分配问题 | LB 不需要考虑报文长度和带宽分配 |
| SWRR (Packet level) | 平滑解决连续打到同一个 RS 的问题 | 每次调度都需要查找并维护,O(N) 初始时以及动态调整权重时,所有 WORKER 相同序列调度压力同一个 RS |
| VNSWRR (RS level) | 预先计算调度顺序,O(1) 调度 打散初始时和调整权重时到 RS 的流量 分步 step 更新减缓调度计算开销 | WORKER 之间不共享,每个单独计算一遍调度顺序表 next_idx 随机范围不是完整的调度顺序表长度 |
从服务器连接状态的角度
我们在测试性能的时候,通常会关注三个指标:PPS(包)、CPS(连接数)、BPS(带宽)。WRR 是从数据包(连接)层面上看调度,DWRR 是从带宽的角度分析(但不符合 LB 处理新连接的需求),现在我们从服务器连接状态的角度看LB
相比于预定义的权重信息,统计当前的连接状态可以更灵活的处理 RS 的调度选择问题
因为 LB 以集群方式部署,本身从 RS 上收集会更能表示其真实的已有的连接状态,但是需要改造 RS 以例如 Sidecar 模式额外的收集信息且对 RS 造成了额外的开销。对 LB 更优的方式是在自己集群内进行全局的统计
minConn
- minConn (最小连接数)
维护对所有 RS 的连接数统计(借会话同步来收集其他 LB 机器上的连接数信息),每次选择当前连接数最少的 RS 调度。通过维护连接数最小堆的方式 O(1) 的选择调度并 O(logN) 的维护。但是由于 WORKER 之间不共享,需要额外的定时任务来收集所有 WORKER 的连接数信息更新到每一个 WORKER 本地,且面对大量的连接数更新,直接重建堆;由于集群内不共享,需要依靠会话同步的方式来获取其他机器的连接数统计
**问题:**WORKER 间不共享、集群内不共享(长短连接)和权重配置
既然应该选择全局(或者说从 RS 角度)的最小连接,在追求效率而不共享的 LB 就需要其他的方式来共享连接数信息。
- 不是从 RS 收集的真实连接数,无法感知其他连接
- 维护非常麻烦,集群内、WORKER 间收集,最小堆维护和定时重建
- 集群内会话同步通常只收集长连接,面对大量持续建立的新短连接没有办法建立全局视野
- 单纯的 minConn 调度时不会考虑 RS 的权重分配,建立连接时只会将本 WORKER 连接数 + worker_cnt
W-minConn 带权重的最小连接数判断:想要再把权重纳入考虑,不同的实现里采用了不同方法
- 建立连接时连接数 ,统计时也直接计算 来建堆(注意这里”权重”越低,“权重”越高 :)
- 除权重后向下取整(爱奇艺 DPVS)
- 两两对比时,(Nginx)
但是实际的上线中,业务并不会根据当前状态去实时调整权重。我们考虑的理想场景例如:有新 RS 上线,由于其当前连接数为 0,会使得有大量连接都打向它。这样的问题确实存在,但不应通过权重的方式来调节
针对这个场景,再考虑其他的解决方案
从完全随机的角度
除了有规律的调度,我们也可以把一切交给天命。哈希的公平性依靠哈希算法的散列程度
通过哈希的方式可以保证相同的明文值每次都会哈希为相同的密文(幂等性),可以额外的保证例如相同的 QUIC CID 转发到相同的 RS 进行处理,或是断开的连接依靠相同的五元组打回与上一次连接相同的 RS
哈希的好处是不需要记录状态,每个新连接根据数据包里的信息来选择调度即可,所以一定程度上哈希可以保证相同的标记会转发到相同的RS
哈希取模
- hash % Mod
最简单的可以想到,对关键字哈希后直接取模RS数量就可以建立到RS的映射。但是由于LB存储都是链表形式,需要额外的数组来保证O(1)的调度选择
根据某一个特定的值进行哈希(随机打散),再对 RS 数量取模
LB 本身存储 RS 是以链表和哈希桶的方式,需要再额外以数组形式存储调度顺序表以保证 O(1) 的调度选择
**问题:**可以看到其调度公平的影响因素为哈希算法和 RS 数量
- 首先需要保证哈希明文的唯一和哈希结果尽量分散,尤其当 RS 数量较少的时候,若再遇到哈希碰撞就会导致很明显的调度不均 -> 填充虚拟节点
- RS 数量变化会导致之前哈希的结果都发生改变 -> 一致性哈希降低影响
从原本的 mod N 哈希方式来看,只有当 hash(k) 的结果对变更前后的两个数量的余数相等时才可能一致
例如 rs num 从 4 变成 5,则 0, 1, 2, 3, 20, 21, 22, 23, …,以两个数量的最小公约数 (least common multiple, LCM) 为一轮,即对 m 和 n,只有 不变
而在一致性哈希中,哈希表槽位数的改变平均只需要对 个关键字重新映射,其中 K 是关键字数量,n 时槽位数
一致性哈希
这里指出在大多数论文中对一致性哈希的要求
- Load Balancing 均衡
在负载均衡上,它要求每一个RS获取任何一个key的机会均衡
-
Minimal Disruption/Remapping 最小化重映射
- 对于新增 RS,已有的 key 映射不变或重映射到新 RS,且总的重映射可控
- 对于删除 RS,已有映射到非此 RS 的映射不变,映射到此 RS 的分散给其他 RS
哈希范围通常不能和可变值绑定
考虑到扩缩容是很常见的事情,一致性哈希希望能减小扩缩容带来的影响
但是对 LB 来说,大多数只需要选择出调度的结果,并不需要对之前的调度结果负责(已由连接状态记录)。但是在 QUIC CID Hash 场景下,哈希带来的影响就更有必要考虑了
这里按照时间顺序整理了一些较为通用或较新的一致性哈希算法
- Rendezvous 哈希 - 1997 - A Name-Based Mapping Scheme for Rendezvous
- 哈希环(割环法) - 1997 - libketama: Consistent Hashing library for memcached clients
- Jump Hash 跳跃一致性哈希 - 2014 - A Fast, Minimal Memory, Consistent Hash Algorithm
- Multi-Probe 一致性哈希 - 2015 - Multi-Probe Consistent Hashing
- Maglev 一致性哈希 - 2016 - Maglev: A Fast and Reliable Software Network Load Balancer
- AnchorHash 一致性哈希 - 2020 - AnchorHash: A Scalable Consistent Hash
- DxHash 一致性哈希 - 2021 - DxHash: A Scalable Consistent Hashing Based on the Pseudo-Random Sequence
Rendezvous 哈希比较特殊
哈希环(割环法)
libketama: Consistent Hashing library for memcached clients
https://www.metabrew.com/article/libketama-consistent-hashing-algo-memcached-clients
1997
- 哈希环(割环法)
哈希值映射到一个大圆环 (2^32) 空间内的槽位,查找时在圆环中顺时针查找映射过的槽位
当往一个哈希环中新增一个槽位时,只有被新增槽位拦下来的哈希结果的映射结果是变化的
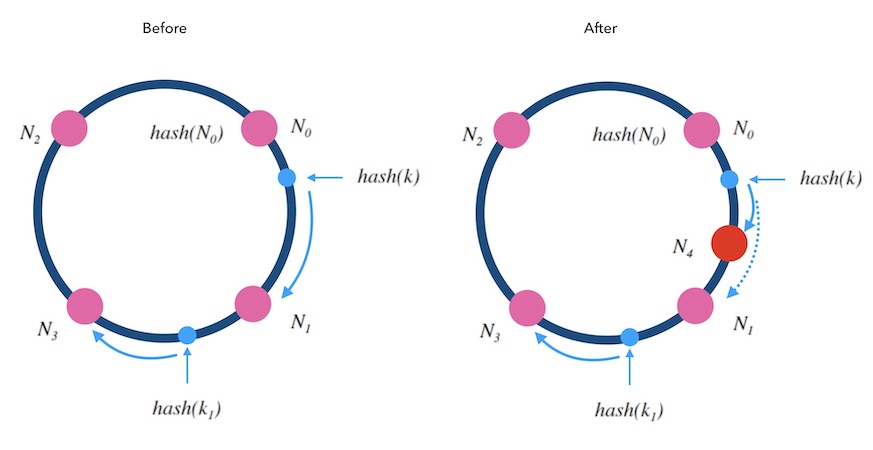
当从一个哈希环中移除一个槽位时,被删除槽位的映射会转交给下一槽位,其他槽位不受影响
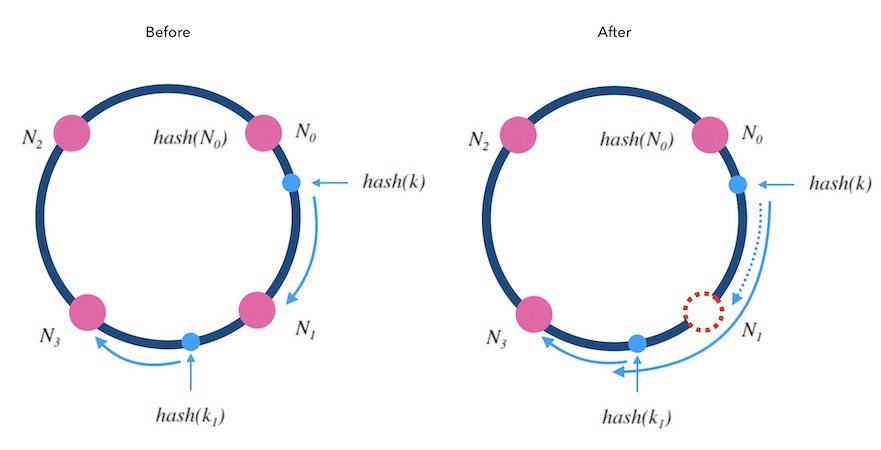
在实际应用中,还可以对槽位(节点)添加权重,通过构建很多指向真实节点的虚拟节点,也叫影子节点。通常采用一个节点创建 40 个影子节点,节点越多映射分布越均匀。影子节点之间是平权的,选中影子节点,就代表选中了背后的真实节点。权重越大的节点,影子节点越多,被选中的概率就越大。但是需要注意的是,影子节点增加了内存消耗和查询开销,权重的调整也会带来数据迁移的工作
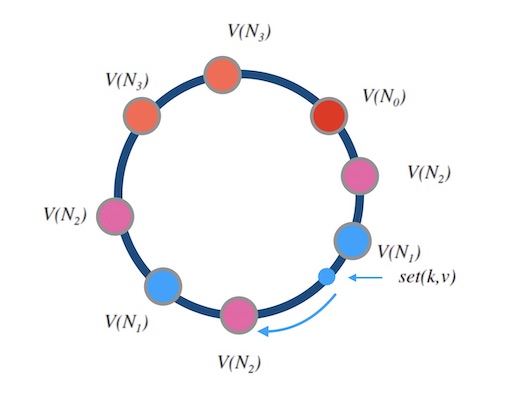
**优势:**一致性哈希和权重分配
**问题:**调度查找开销和额外空间开销
- 调度时需要在哈希环中顺序的查找到槽位(或虚拟节点),造成额外的查找开销 -> 预先填充整个哈希环,应该可以看作 O(1) 调度查找
- 需要开辟大量空间用来做哈希环和影子节点
- 哈希环算法的映射结果不是很均匀,当有 100 个影子节点时,映射结果的分布的标准差约 10%;当有 1000 个影子节点时,降低到约 3.2%
实际的实现方式:
- 平铺预填充,对 hash 值范围进行限制,将 RS 指针直接填充到 hash 范围大小的数组里 O(1) 查找。如果是 32bits 的哈希范围,就代表需要开辟 sizeof(ptr) * pow(2, 32) 大小的数组,4 字节指针时总存储约为 17GB。如果是 16bits (65536),需要 256KB
- 建立以影子节点 hash 值排序的虚拟节点链表,并在这基础上以类似跳表的形式加速查询时 hash 定位影子节点。但跳表的层数和删除,逻辑复杂
hash_ring {
len; // shadow_node length = sum(node * weight * shadow_cnt)
shadow_node *list;
jump_list[level][jump_node] = {};
}
shadow_node {
*rs;
hash;
*next_shadow_node;
}
jump_node {
hash;
*shadow_node;
*next_jump_node;
*next_level_jump_node;
}- 改为用数组存储虚拟节点表,同样以影子节点的 hash 值排序。查找时对查询的 key hash 值二分查找,简化逻辑(普遍选择的做法)。查询同样是 O(logN)。但是这样当添加和删除RS时,都需要重新排序,且可能需要重新分配数组空间
Jump Hash 跳跃一致性哈希
- Jump Hash 跳跃一致性哈希
A Fast, Minimal Memory, Consistent Hash Algorithm
https://arxiv.org/abs/1406.2294
2014
int32_t JumpConsistentHash(uint64_t key, int32_t num_buckets) {
int64_t b = -1, j = 0;
while (j < num_buckets) {
b = j;
key = key * 2862933555777941757ULL + 1;
j = (b + 1) * (double(1LL << 31) / double((key >> 33) + 1));
}
return b;
}这个算法想直接看懂有点困难,上面这一段就是论文中最终实现的Jump ConsistentHash算法的代码,简短且优雅且难以理解
它是从一致性哈希的重映射数量上出发考虑,当槽位数量发生变化时,我们只需要限制只有K/n的重映射即可,那么我们只需要保证每次变化都只有这么多的重映射会发生,并且为了均匀性,我们要求这些重映射都映射到新增加的槽位节点里,这样每一个槽位里都有约K/n数量的key
由于是通过伪随机的方式,并将哈希 key 作为伪随机数种子,对于给定的哈希槽位数量,key 的映射结果都是唯一确定的。伪随机的作用是,同一个key不管是什么时候,生成的随机数序列是固定的,那么它们发生重映射的时间(即在添加第几个槽位的时候发生了重映射)就是确定的
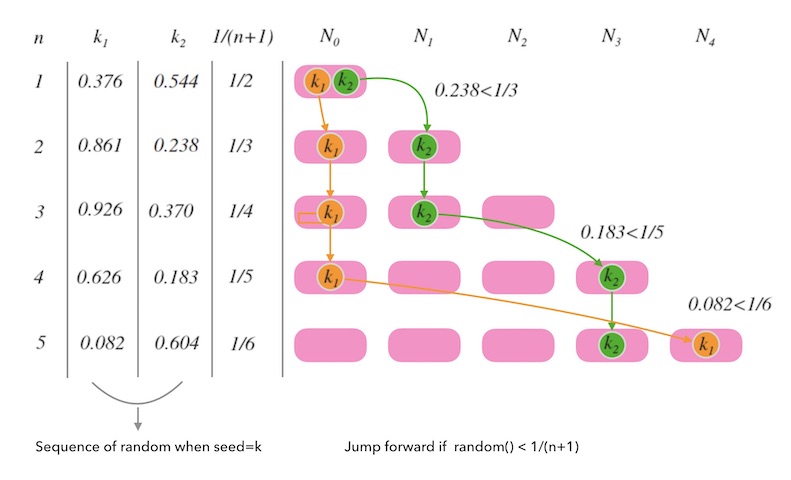
在这张图里可以看到,每次RS增加时,都会对key再生成出一个随机数,如果随机数小于阈值1/n就会把它重映射到最新的一个槽里。例如这里的k1和k2随机过程。注意是重映射进最新的槽,而非它的下一个槽
换个角度想,就是每次都有1/n比例的key会从前面任意的槽位跳到新槽里
「伪随机哈希优化」
在上面的实现里,需要判断 N 次伪随机值来确定是否要跳跃到当前的最大桶上,计算哈希所需要花费的时间时间 O(N)。但是注意到元素只有很小的概率会移动,它只会在桶增加时移动,且每次移动都必然移动到最新的桶里,即如果一个元素移动到 b 号桶(从 0 开始计号)里,必然是因为桶增加到 b+1 个导致。所以我们只需要求出下一次移动的目标 j,即可跳过 b+2 … j 次伪随机的步骤
下一次移动到 j 意味着 b+2 … j 都伪随机到了不移动。另我们知道当桶增加到 N 个时元素的移动概率为 1/N,不移动的概率为 (N-1)/N。所以元素移动到 j 的概率 Pj 为
那么我们可以改变思路,将 Pj 作为伪随机的值 r,就可以直接通过伪随机值来获取 j 了
优化前的代码为
int consistent_hash(int key, int num_buckets) {
srand(key);
int b = 0;
for (int n = 2; n <= num_buckets; ++n) {
if ((double)rand() / RAND_MAX < 1.0 / n)
b = n - 1;
}
return b;
}优化后的代码为
int consistent_hash(int key, int num_buckets) {
srand(key);
int b = 1, j = 0;
while (j < num_buckets) {
b = j;
r = (double)rand() / RAND_MAX;
j = floor((b + 1) / r);
}
return b;
}最终将跳跃一致性哈希算法的时间优化到 O(logN)
**优势:**在执行速度、内存消耗、映射均匀性上都比哈希环算法更好,时间可以由 O(N) 优化至 O(logN)
问题:
- 无法自定义槽位标号,必须从 0 开始,意味着需要 rs_buf 数组
- 只能在尾部增删节点,导致删除中间节点 i 需要先把后面所有的 [i:] 都删掉,再把 [i+1:] 的添加回来 -> LB 不需要持久化连接(维护已建立过的连接 key)不需要管
「实际的实现方式」
- 在负载均衡调度的场景下,如果一个连接建立后断开,下一次又来建立连接,就要看是否需要重回到之前的调度,这也是一致性哈希想要控制的问题。如果不需要对持久化做 100% 保证,那么跳跃一致性哈希就不需要维护 key 的移动,仅仅需要使用
JumpConsistentHash选择出调度的 RS 即可
RS_idx <- JumpConsistentHash <- key(srcIP or QUIC cid), RS_numRS a 添加:
- 向 RS 数组后直接添加一位 RS a 即可,
RS_num++,Jump Hash 时根据RS_num数量来跳跃映射 RS b 删除: - RS 数组直接删除 RS b,b 之后位置的 RS 都向前移动一位
- 每次删除造成 数量的重映射
- RS 的 not alived 状态无法处理
- RS 数组将 RS b 标记为 not alived,其余 RS 不动
- 不破坏整个 RS 数组,将删除 RS 和健康检查等价。添加 RS 时先检查是否是之前标记为 not alived 状态的 RS,如果没添加过才会放到数组末尾
- 维护总
RS_num和alived_RS_num,当JumpConsistentHash(key, RS_num)映射到 not alived 状态的 RS 时,根据alived_RS_num重新计算映射结果 - 每日流量低谷时整理 RS 数组,清理实际为删除的 RS,降低重映射的代价
但是由于维护了有序的RS数组,当我们在做RS删除时,如果像第一种方式,把后面位置的RS向前移动,就会在每次删除都造成 (rs number - b) * key / (rs number - 1) 数量的重映射,且当哈希到一个非存活状态的RS时需要单独考虑如何处理
我现在能想到的解决方案就是把中间位置删掉的RS看作not alived状态,不去移动后面的RS位置。这样我们的RS number也没有变,整个Jump Hash都不会变化。
注意我们没有破坏RS数组,并且我们尝试维护总RS数量和当前存活的RS数量,当Jump Hash映射到了一个not alived状态的RS时,就根据当前存活的数量来保证一定可以找到一个可行的调度结果。这有点类似后面要介绍的AnchorHash的思想
最后,我们也不能放任删除的RS不管,这样如果变动较多,RS数组就会无限增长了
Multi-Probe 一致性哈希 (MPCH)
- Multi-Probe 一致性哈希
Multi-Probe Consistent Hashing
https://arxiv.org/abs/1505.00062
2015
目标:灵活调节节点大小和降低方差
基本思想是在哈希环的基础上查找时对 key 进行 k 次哈希,返回所有哈希查询中距离最近的节点。k 的值由所需的方差决定。对于峰均值比 1.05(负载最重的节点最多比平均值高 5%),k 为 21。作为对比,哈希环算法需要 700lnN 个副本。对于 100 个节点,这相当于超过 1MB 内存
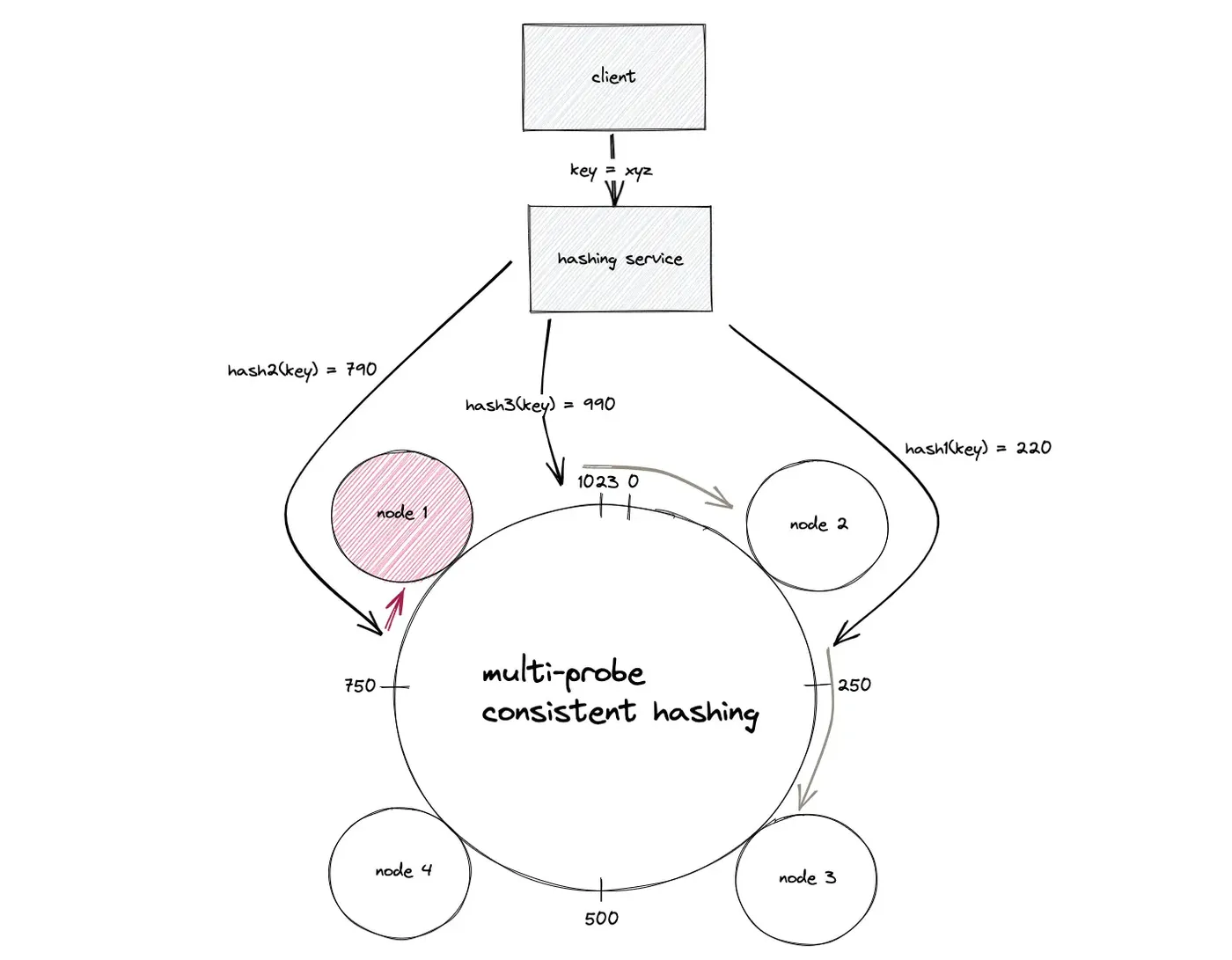
通过这样的方式,可以很好的解决哈希环中节点负载不均匀的问题。因为在哈希环算法里,这个随机位置的哈希值会截获它逆时针方向上所有的key,不均匀就体现在节点截获的范围都必然有很大的区别。理想上只有像图里这样的哈希环,四个节点均匀的把圆环等剧划分才会是均匀分布的。而MPCH将截获范围改为了离得最近的节点,这样就意味着原本离得远但是也被截获的key现在会因为距离不如别的结果而被舍弃掉,从而实现更为均衡的分配结果。
但是在实现上需要根据想要的均匀程度来提高k哈希的次数,这对调度来说是一笔很大的时间开销,它约等于进行了K次哈希环调度。而想要实现比较高的均匀性,k这里已经需要21次哈希环调度的时间。但是好处是,它不再需要像哈希环那样创建大量的虚拟节点来保证分配的均匀性
Maglev 一致性哈希
- Maglev 一致性哈希
Maglev: A Fast and Reliable Software Network Load Balancer
https://research.google/pubs/maglev-a-fast-and-reliable-software-network-load-balancer/
2016
Maglev是基于我们前面提到的,要把取模和RS数量解耦的思想,建立固定长度(且一定超过可能的RS数量的)查找表并填充,这样就可以取模固定长度然后O(1)的确定下调度选择了
计算查找表需要为每个槽位生成一个偏好序列 Permutation,按照偏好序列中数字的顺序,每个槽位轮流填充查找表。如果填充的目标位置已被占用,则顺延该序列的下一个目标位置填充
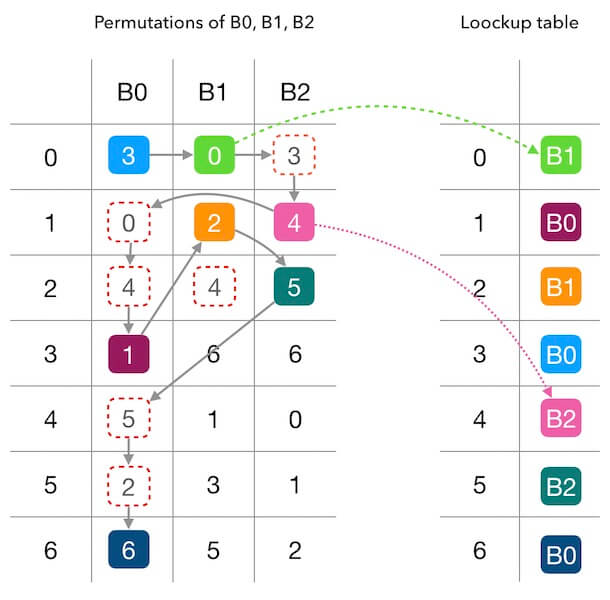
伪代码

由于存储了偏好序列表,槽位的变动对查找表的影响就是可控的了
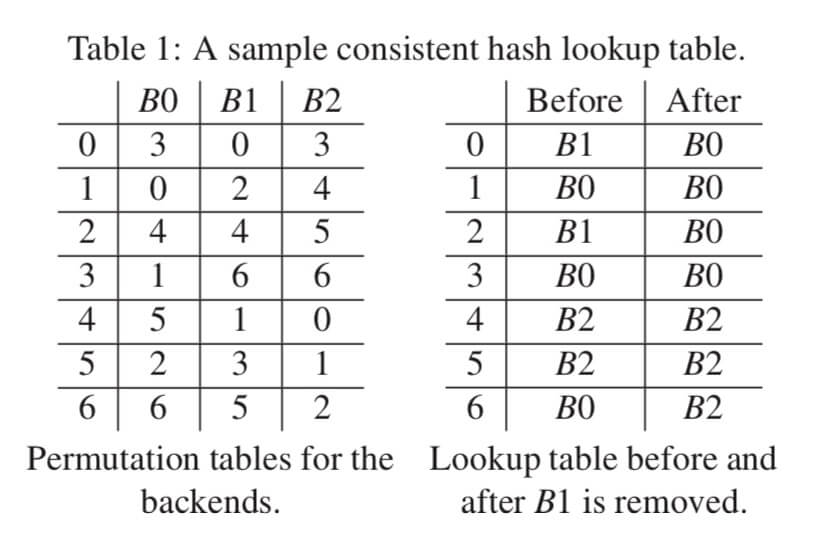
这里的图源自Maglev论文,根据左边的偏好序列,在B1删除前后的查找表变化只有0,2,6。但是需要注意的是,0和2是因为B1删除直接影响的,6是被间接影响的部分
生成偏好序列的方式有很多,只需要保证其随机和均匀。查找表的长度 M 应是一个质数,这样可以减少哈希碰撞和聚集,让分布更均匀。查找表建立时间 O(MlogM),最坏 O(M^2)
如果想要实现带权重的 Maglev 哈希,可以通过改变槽位间填表的相对频率来实现加权
关于时间复杂度计算,可以参考 Maglev 哈希的复杂度分析
「随机生成偏好序列 permutation」
Google 方法是,取两个无关的哈希函数 h1 h2,给槽位 b 生成时,先用哈希计算 offset 和 skip
然后对每个 j,计算
这里通过类似二次哈希的方法,使用两个独立无关的哈希函数来减少映射结果的碰撞次数,提高随机性。但是这要求 M 必须是质数,才能保证与 skip 互质,最终遍历完整个 M
Google 论文中说核心关注的两个问题是:
load balancing: each backend will receive an almost equal number of connections.
minimal disruption: when the set of backends changes, a connection will likely be sent to the same backend as it was before
其中第一个是最为关键的,同时 Maglev 每个 VIP 绑定到后端的几百个服务器,每个都需要很大的 lookup table。并且,尽管想要最小化一致性哈希在扩缩容场景下的变化,但因为有 connections’ affinity 亲和性 (conntrack) (且连接复用的 reset 也是被允许的),少量的槽位增删干扰也是可以接受的
**优势:**O(1) 的调度查找、均匀且一致性的哈希映射和可以增加权重的影响
问题:
- 需要额外存储每个槽位的偏好序列和槽位查找表 (rs_buf)
- 虽然避免了全局重新映射,但是没有做到最小化的重新映射
- Google 的测试里,65537 大小的查找表生成时间为 1.8ms,655373 大小的查找表生成时间为 22.9ms
问题1在实际的实现里,我们只需要存储查找表,每个RS的偏好序列只需记录offset和skip就可以,详细可参考DPVS的源码实现
有关最小化重映射的问题,尽管我们不能直接的进行分析,但可以通过尝试构造反例的方法来初窥它的重映射问题。注意我们刚才提到的RS变化对查找表的影响会分为直接和间接两部分。直接的肯定不需要说,那么我们的反例就需要尽可能放大间接影响的部分
这里我们以三个RS为例,尝试生成他们的偏好序列。在左边的偏好序列下,查找表会用[num]的部分,计算出ABC表。右边删除A服务器后,所有的选择都被直接或间接影响了,计算出了BCB表。这里是100%的重映射
| A | B | C | Entry | -> | B | C | Entry |
|---|---|---|---|---|---|---|---|
| [0] | 0 | 1 | A | [0] | [1] | B | |
| [1] | [2] | B | 1 | 2 | C | ||
| 2 | C | [2] | B |
当我们继续扩大表长度,想要维持和刚才一样的影响,[num]的新增部分就需要和前面一样,使得它在4-6的位置也是全部重映射
| A | B | C | Entry | -> | B | C | Entry |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | A | 0 | 1 | B | |
| [3] | 1 | 2 | B | 1 | 2 | C | |
| 2 | C | 2 | B | ||||
| [3] | [4] | [A] | [3] | [4] | [B] | ||
| [4] | [5] | [B] | [4] | [5] | [C] | ||
| [5] | [C] | [5] | [B] |
但是注意Google论文中使用的偏好序列生成方式,permutation是根据skip连续的,这里的话B服务器offset 0,skip 1,C服务器offset 1,skip 1
当我们把C服务器偏好序列的连续有规律变化考虑进去,就会影响刚才计算查找表时的选择了,最终5和6都没有被间接影响
| A | B | C | Entry | -> | B | C | Entry |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | A | 0 | 1 | B | |
| 3 | 1 | 2 | B | 1 | 2 | C | |
| 2 | [3] | C | 2 | [3] | B | ||
| 3 | 4 | A | 3 | 4 | [C] | ||
| 4 | 5 | B | 4 | 5 | [B] | ||
| 5 | C | 5 | [C] |
如果我们再把权重影响的填表频率再纳入考虑呢?就更复杂了
这个反例是想说,几乎不可能构造出间接影响很大且符合生成规则的偏好序列,总体上Maglev的重映射问题是可控的
「槽位增删分析」
Experiments in Google Paper Section 5.3
实验设置:1000 台后端服务器,对每个 k-failure 重新生成查找表并检查入口变化,重复 200 次取平均值
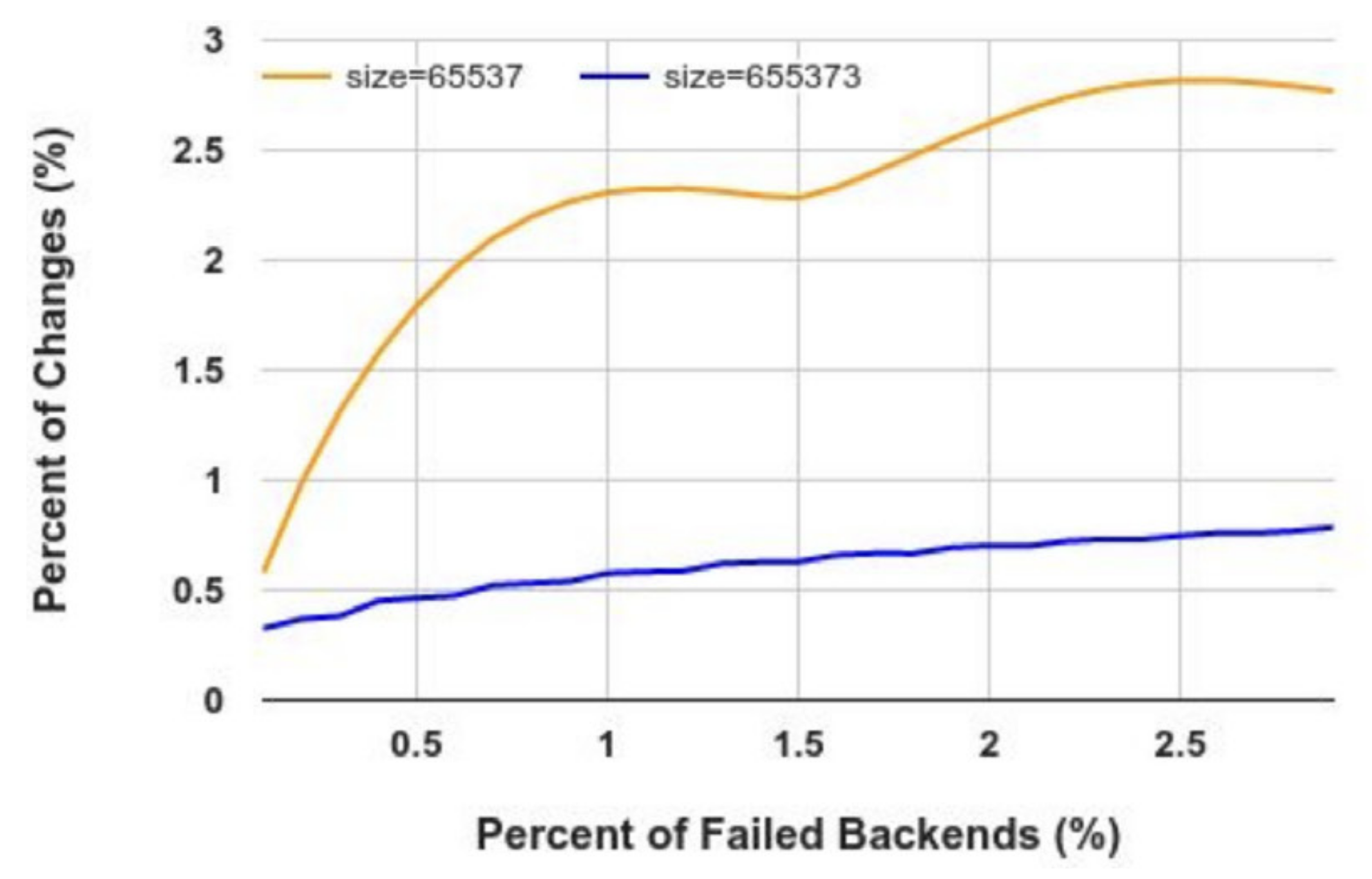
按照实验结果,M = 65537,k = 5 时,只有约 1180 个入口会变化 (约 1.8%)
AnchorHash 一致性哈希
AnchorHash: A Scalable Consistent Hash
https://arxiv.org/abs/1812.09674
2020
- AnchorHash 一致性哈希
池化+标记的思想,通过复用来减少重映射
想解决槽位增删时的高迁移成本和平衡性下降问题
预先定义固定大小 a(预期可能达到的最大节点规模)的虚拟节点集合为锚点集,工作节点是锚点集的子集
当对 key 分配时,
- 先用 H1(key) 映射到锚点集的一个桶 b
- 如果桶 b 是工作节点,则直接分配
- 否则启动回填过程
- 用另一个哈希 H2(key) 计算一个起始点
- 在锚点集按顺序查找下一个是工作节点的桶 b’
不过上面这只是理想的AnchorHash查找步骤,实现上需要很多优化在里面,比如这个hash2如果真的取模RS数量一定会造成它无法实现最小化重映射,它设计了一个next数组来维护当前桶不可用的时候回填过程应该怎么走,在节点增删时维护 next 指针

直接说算法可能比较抽象,AnchorHash在算法和代码上都非常难以理解。这个图是它抽象出来比较好理解的一个
左边是算法的变化,W代表所有在工作的RS节点,Wb代表对应的节点删除之后的一个记录,实际上也就是第一次映射到当前节点发现不存在时,进行回填的查找范围。可以对照左边删除节点后记录的Wb来看右边的查找过程。如果k1哈希后直接找到工作节点,那么就可以直接返回。如果k2哈希后找到了一个空节点,它就会在这个节点记录的Wb范围里再随机下一个位置,直到找到了工作节点。可以看到如果是删除之后,此时添加节点 5,就会导致节点 1 上的重映射是不均匀的了,因为它的哈希范围不包括节点 5
所以需要用一个栈来维护删除的节点,当有新节点添加时,添加的位置是栈顶最近删除的节点的位置。栈标记不仅仅是加速,也是维护均衡

M: Mapper from anchor A to rs S
R: Removed label
这个就是AnchorHash众多版本的伪代码里最容易理解的一个。M代表刚才W向S的一一映射关系,R代表我们维护的节点删除栈,A\W代表A-W的部分,HWb就代表它哈希的范围是Wb
右边是对AnchorHash的封装层。在初始化的时候,它先把目前已有的工作RS分别添加到M最终的查找映射和W工作列表里,然后把A中非工作节点都倒序的压栈,这样我们在添加节点的时候对A数组来说就是从前到后的添加。这里A\R就是我们刚才的Wb列表,表示如果第一次映射到当前节点,那么下一次应该在哪个范围里查找。获取资源就是先哈希到一个位置看是否是工作节点,如果不是就根据它的Wb信息继续查找。最后找到的结果再从M里确定唯一的RS。添加RS是从栈顶拿最近删除的节点位置添加。删除节点除了从工作列表里去掉,还需要维护它的Wb范围(即当前的其他节点)、压栈、删除M映射关系
按照作者一通复杂的计算,获取资源GetBucket的时间是 1+ln(a/w),1是第一次哈希映射,后续回填查找平均需要后面这部分时间
优势:
- 删除节点时,只影响直接映射到该节点桶以及通过回填路径依赖该桶的 key
- 存储固定大小的数组记录,不需要虚拟节点
- 查找通常只需要一次初始哈希和平均不到一次回填跳转
- 不会因为其他节点的增删而影响当前节点的映射 key
- 负载平衡性高较均匀,键分配到工作节点的方差较低。但实际上在后面的实验里我们会发现它的负载平衡性非常差。这个的原因是,在官方提供的源码实现里,A\W部分的回填都会指向最后一个工作节点。也就是说在不发生RS增减时,会有A-W/W比例的key映射到最后一个节点,而非它算法所说的根据W节点数量重新随机。所以从它源码实现的角度来理解,AnchorHash更适合槽位只在小范围变动且W数量接近A的场景
问题:
- 额外的内存开销来存储三个 O(a) 数组 workers, removed, next
- 新增节点只接收映射到它自身桶的新键和未来因其他节点离开而回填的键,不会立即分担现有节点的负载
- 需要维护 next 指针的逻辑较为复杂
DxHash 一致性哈希
DxHash: A Scalable Consistent Hashing Based on the Pseudo-Random Sequence
arxiv.org/pdf/2107.07930
2021
- DxHash 一致性哈希
DxHash是这里面最新的一个算法,大概在21年最早提出,在23年(两年前)才落地公开。但是也可以说是里面最简单但奇怪的解法
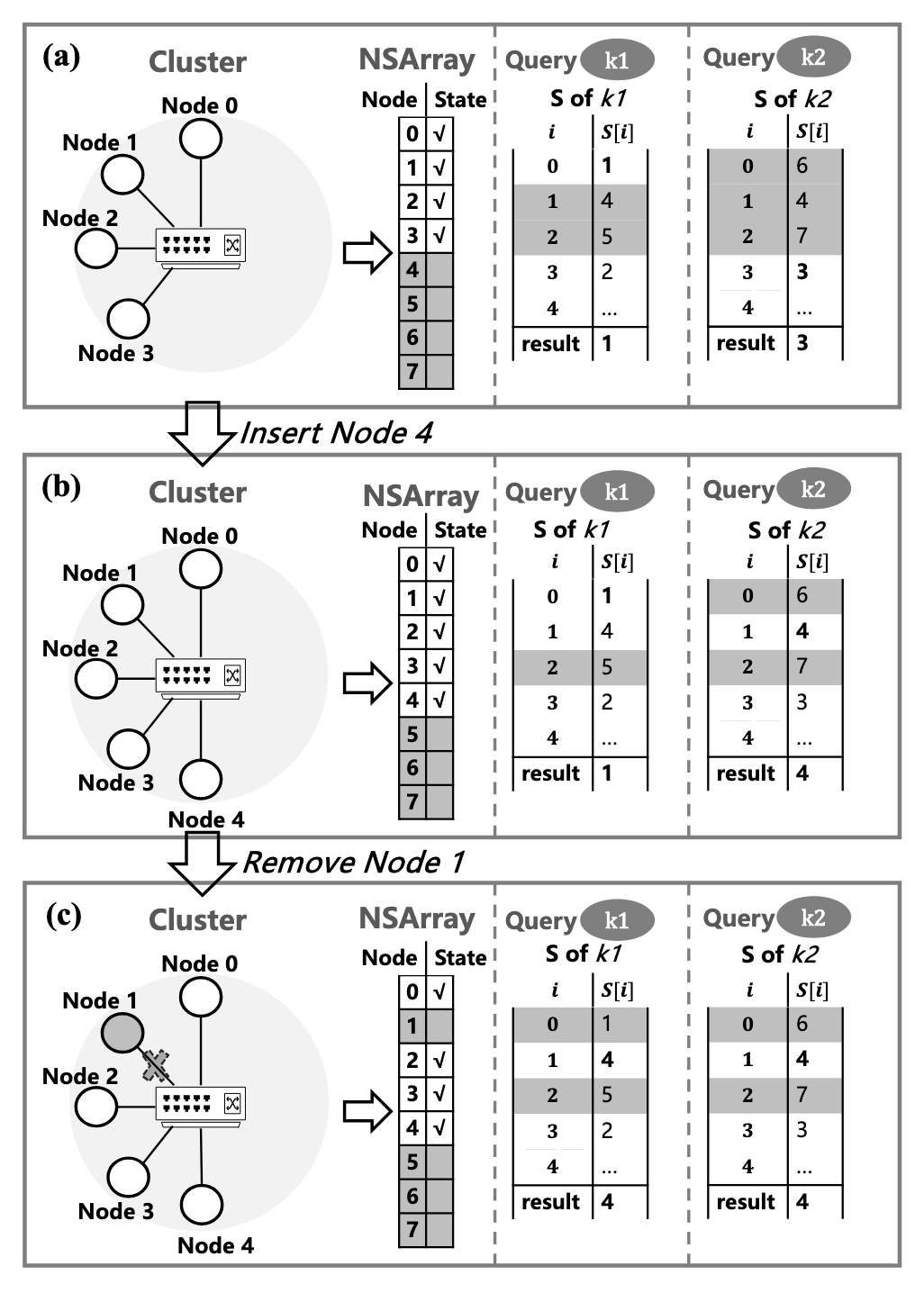
它维护了一个NSArray数组,长度为大于 RS_num 的最小 值,例如 RS 是 4 台,则 NSArray 长度为 8
通过伪随机数机制来保证同一个 key 有固定有序且无限长度的服务器序列
Minimal Disruption: the changed node is either the original or the destination of the remapped keys.
为了防止无限长的服务器序列一直映射不到活动节点,DxHash 对搜索的次数限制到 8n,n 为 cluster size
当 n 足够大时,P 接近 ,约为 0.03%,作者认为概率足够小可以忽略
NSArray开了额外的空间是为了保证当有新RS节点添加时可以直接塞进去,但是总有满的时候,这时就会发生两倍的扩容和节点迁移
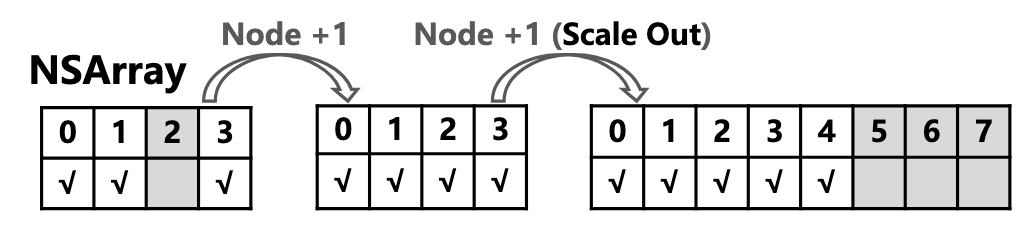
类似Golang的切片,我们可以提前开辟足够大的空间来让它不会发生节点迁移
「质疑」作者没有讲 NSArray 扩容后出现的大量变化的重映射问题,只说它会像传统哈希算法那样调度。在DxHash的公开源码实现里也直接不管扩容的重映射问题,这也是我对DxHash算法的质疑,可能作者认为两倍空间通常是足够RS扩缩容的
When the cluster reaches its maximum capacity and all items in the NSArray are active, DxHash behaves as a classic hash algorithm that maps objects to nodes with a single calculation.
权重通过虚拟节点层实现
一致性哈希算法对比
这个对比表是从大佬的博客里偷来的,它从理论上对比了各个算法的内存占用,查找时间等
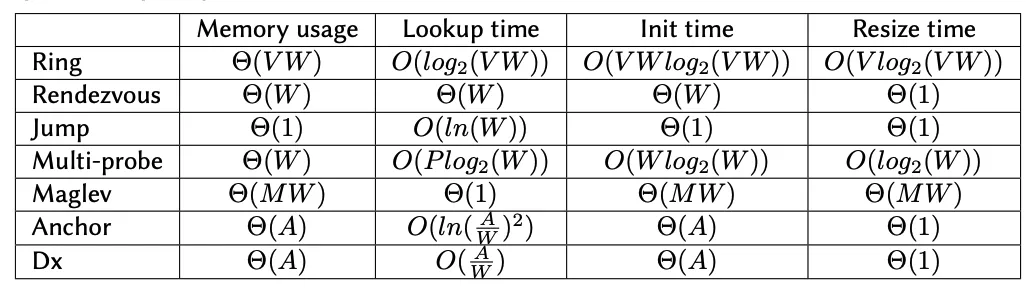
- 𝑉:ring 中每个物理节点对应的虚拟节点个数
- 𝑊:集群中的 working 节点数目
- 𝑃:Multi-probe 中的探针(哈希)个数
- 𝑀:Maglev 中每个节点在查询表中的位置数
- 𝐴:集群中的所有节点数(包括 working 和非 working 的节点)
我们重点关注的是中间两个,查询时间和初始化时间。在一致性哈希算法中,只要不是真的把哈希环全部预填充出来或是为了极致的均衡性需要开辟特别大的空间,内存占用是比较可控的
在查询时间上,Maglev是预填充的O(1),较快速的是Jump Hash和AnchorHash这种log级别的。哈希环就需要填充大量的虚拟节点来均衡
大部分算法都需要花时间来维护状态,只有Jump Hash完全只取决于伪随机数
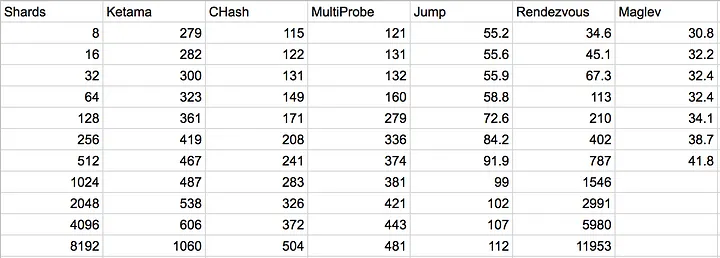
不同节点数量时单次查询的时间(纳秒)
在博客里,他测试的在不同RS数量时,单词查询所花费的时间
可以看到Rendezvous哈希和RS数量强相关且增长很快
Maglev因为是O(1)查找,变化不会很大。同时Jump Hash的时间控制的也比较好
我比较质疑的是这里Multi-Probe的时间,理论上他会进行k个探针的k次哈希环查找,然后选择最近的一个。但这里的时间居然比Ketama哈希环还要快得多
所以,我自己尝试对这些算法进行了一些简单的小测试。需要注意有的我标记了是在本地跑的实验结果,旁边会有对应的在服务器上测试的时间结果
- CHash 算法对比 - 分布均匀性测试
测试条件:100个节点,100,000个键

分布均匀性测试衡量的是当大量键被分配到固定数量的节点时,每个节点被分配到的键数量是否接近平均值。我们使用标准差来衡量分布均匀性:
- 标准差越小:表示各节点被分配到的键数量越接近平均值,分布越均匀
- 标准差越大:表示某些节点被分配到的键数量远高于或低于平均值,分布不均匀
可以看到前四个算法在分布均匀性上都表现较好,都实现了基本完全随机的分布。哈希环算法在每个节点映射出160个虚拟节点时表现较好,而MPCH在没有虚拟节点的情况下,通过增加探针数量控制住了分布均匀性,在哈希环中实现了内存与分布均匀性的trade off。AnchorHash因为A列表和W节点数差距很大,在官方的实现方式里它会把A\W的部分都映射给最后一个节点,所以分布均匀性很差
- CHash 算法对比 - 查询性能测试
测试条件:1000个节点,100,000个键

性能测试衡量的是算法处理单个键查询的速度
时间为 100,000 个键查询总时间
前三行是O1的查找,时间区别主要在查找表长度
跳跃一致性哈希和哈希环是O(logN)级别的查找,且跳跃一致性哈希是在RS数量次数内无状态的计算随机数,比创建大量虚拟节点的哈希环更快
两个新算法都需要考虑创建的A列表和W列表的长度比,且AnchorHash在实验中A-W范围很大,回填较慢
Rendezvous哈希需要给每个键计算所有RS的哈希值再找最大,MPCH也需要进行k次的映射尝试找结果,都需要很长的时间来查询
- CHash 算法对比 - 添加节点时的重映射测试
测试条件:1000个初始节点,新增10个节点,100,000个键

重映射测试衡量的是当系统中增加新节点时,有多少比例的键需要重新分配到不同的节点:
- 重映射比例越低:表示系统扩展时对现有服务的影响越小
- 重映射比例越高:表示系统扩展时对现有服务的影响越大
像我们刚才说的一致性哈希希望能保证只有K/n数量的重映射,那么每添加一个节点,这里就应该只有10w/约1000也就是约100次的重映射,约占总key的0.1%。总共添加10个节点,有一些节点也会发生多次的重映射,所以最终可以看到除Maglev都基本控制到了最佳的重映射比例,Maglev也只有3%的key发生了重映射
后面的添加节点耗时一定程度上反应的是是否需要重新计算或扩充存储。由于实现方式可能会发生切片扩容的原因,前面的算法耗时差异可以忽略,只有最后两个时间较长:哈希环需要填充虚拟节点然后重新比较来排序,Maglev需要重新计算调度顺序表
(没有做节点删除的重映射测试是因为JumpHash删除节点的方式没有确定,DxHash删除节点的缩容也没有明确定义
- CHash 算法对比 - 性能综合对比

- 查询性能优先:选择直接哈希取模或 Maglev 哈希
- 最优分布均匀性:选择 Jump Hash 跳跃一致性哈希
- 平衡各方面需求:选择 Jump Hash 或 Maglev 哈希或哈希环算法,并适当调整虚拟节点数
- 对重映射极其敏感:选择AnchorHash
最终列出了在不同场景下的算法选择
追求极致的查询性能就选Maglev的O1查询,但刚才实验也表明JumpHash也有很好的查询时间开销
大部分一致性哈希算法都做到了较好的分布均匀性,其中JumpHash最优
比较平衡的选择是JumpHash、Maglev和哈希环
想要追求极致的最小化重映射可以选AnchorHash,但它的列表长度需要再多考虑一下
Rendezvous 哈希
A Name-Based Mapping Scheme for Rendezvous
http://www.eecs.umich.edu/techreports/cse/96/CSE-TR-316-96.pdf
1997
- Rendezvous Hash
Rendezvous这个词意思是约会,这个算法的实际含义是:和所有RS都约会一遍,然后确定那个最好的。所以它其实是渣男算法
为了和RS数量解耦,Rendezvous会为每个key生成一个随机有序的RS序列,并选择第一个RS作为目标。和RS的约会过程就是把key自己和RS id合起来进行哈希得到一个随机值,然后把所有RS的随机值进行排序
「核心思想」
如果只是对服务器 ID 进行哈希,那么当修改服务器的数量时,所有的哈希值都会发生变化。当对目标服务器的选择和服务器的数量没有直接关系时,就可以避免服务器的增删带来的影响
「算法思路」
为每个 key 生成一个随机有序的服务器列表,并选择列表中的第一个作为目标服务器
如果选择的第一台服务器下线时,只需要将 key 转移到列表中的第二台服务器并作为新的第一台服务器即可
- 对每个服务器计算 key:rs_id 哈希来生成一组整数哈希值
- 基于该哈希值对服务器进行排序,得到一个随机排列的服务器列表
对于有权重分配的场景,可以基于 w / lnh(x) 排序,h(x) 哈希范围在 [0, 1]
优势:
- 将服务器选择和数量完全解绑,并提供了第二选择服务器,解决了哈希级联故障转移的问题
- 没有额外的内存存储开销
**问题:**调度的时间开销和扩容影响第一选择
- Rendezvous 哈希进行调度时需要对所有 RS 进行哈希计算并排序,时间开销 O(NlogN)。实际上在取 RS 哈希时应该先检查存活,所以只需要 O(N) 查找哈希值最大的一个即可
- 扩容时新服务器可能成为一些已有 key 的第一选择,所以很难维护第一选择的不变。在分布式存储场景下需要重新校验所有 key,但在缓存和负载均衡场景下影响可以接受
「变体」
后来又提出了类似跳表的优化方案,通过建立层级关系,我们可以像这里动图这样O(logN)的时间找到对应的RS,但这样也就意味着需要维护层级关系了
调度时间优化至 O(logN)。把原始节点分成若干个虚拟组,虚拟组一层一层组成一个“骨架”,然后在虚拟组中按照 Rendezvous 哈希计算出最大的节点,从而得到下一层的虚拟组,再在下一层的虚拟组中按同样的方法计算,直到找到最下方的真实节点
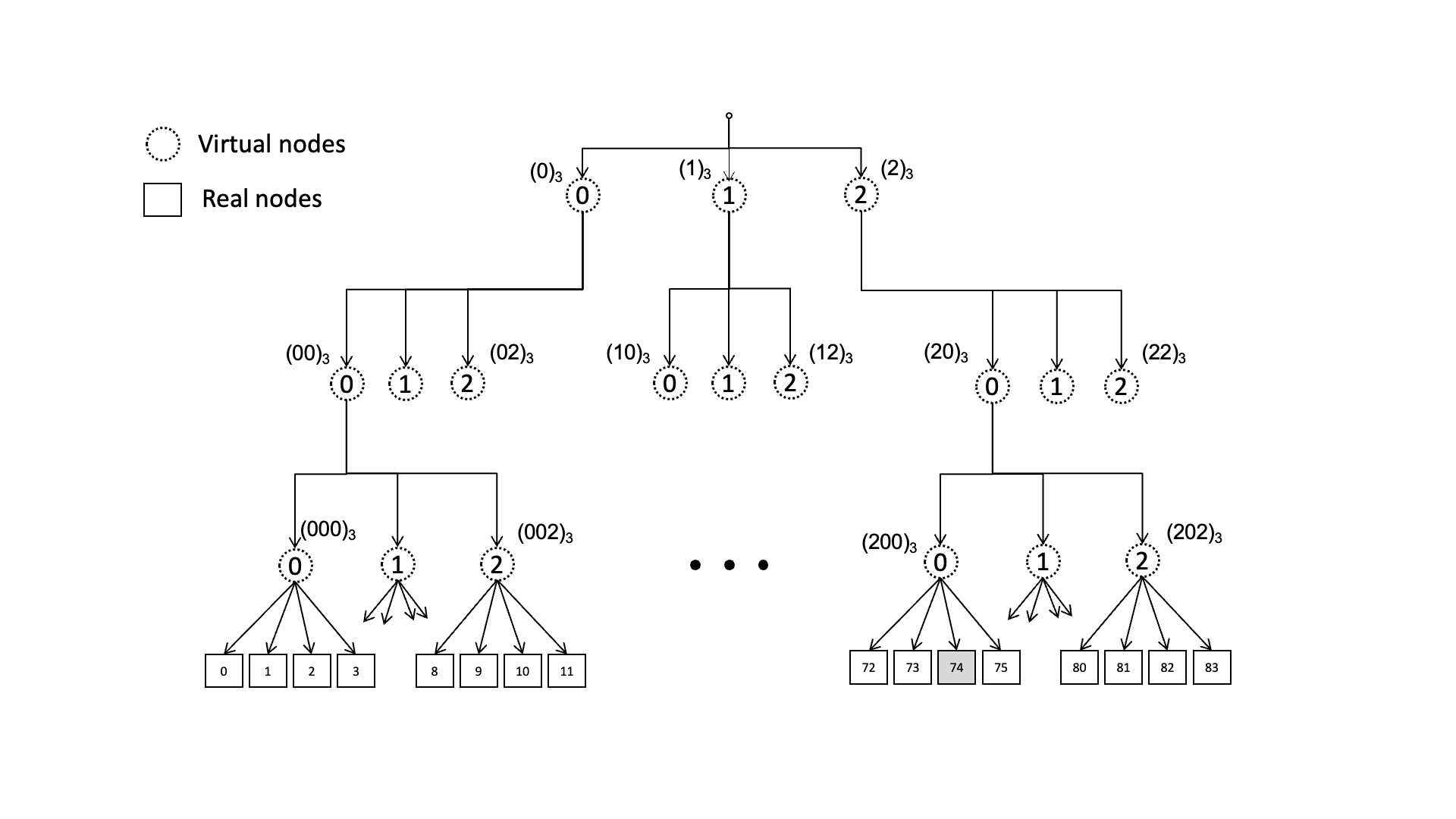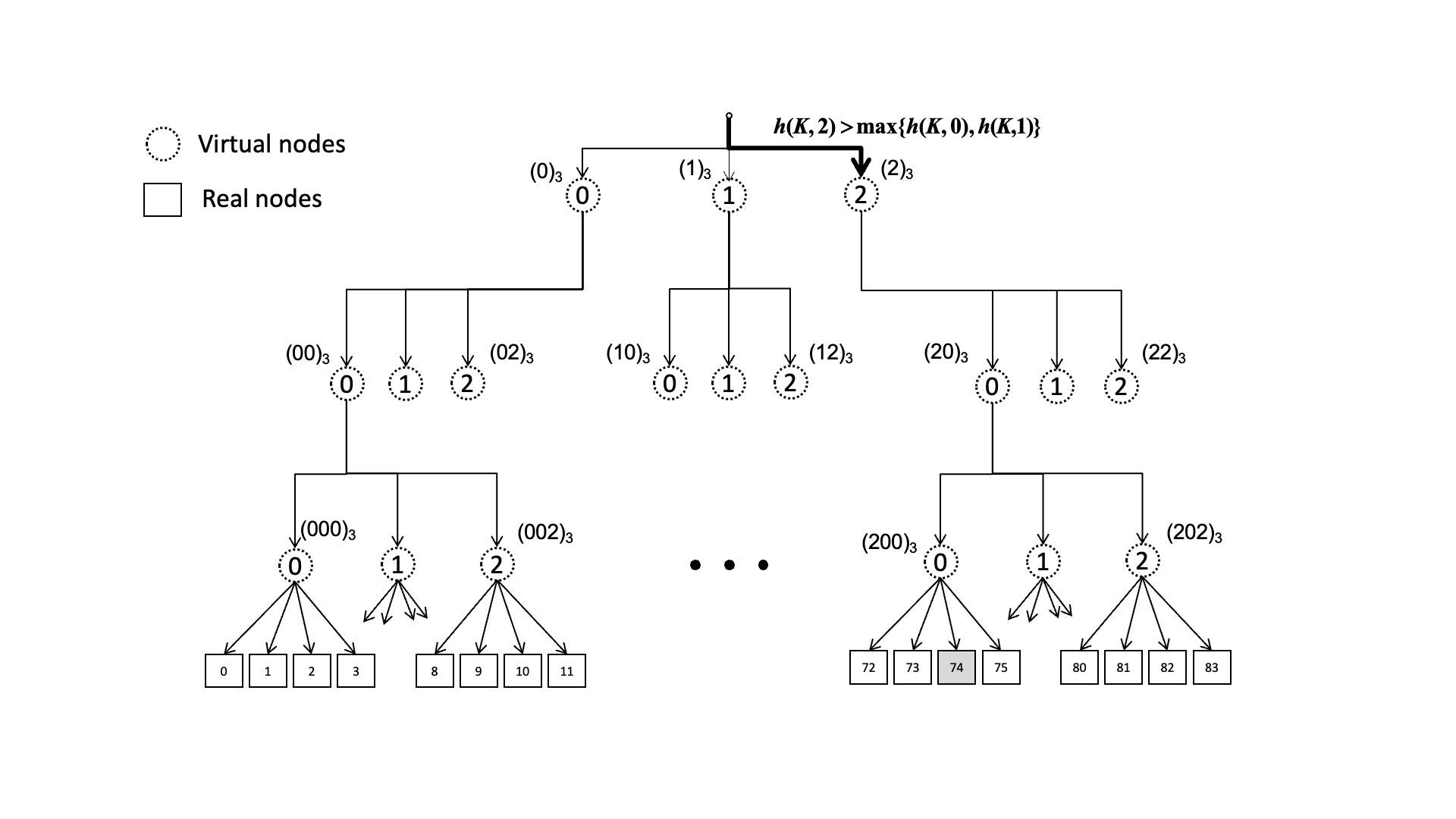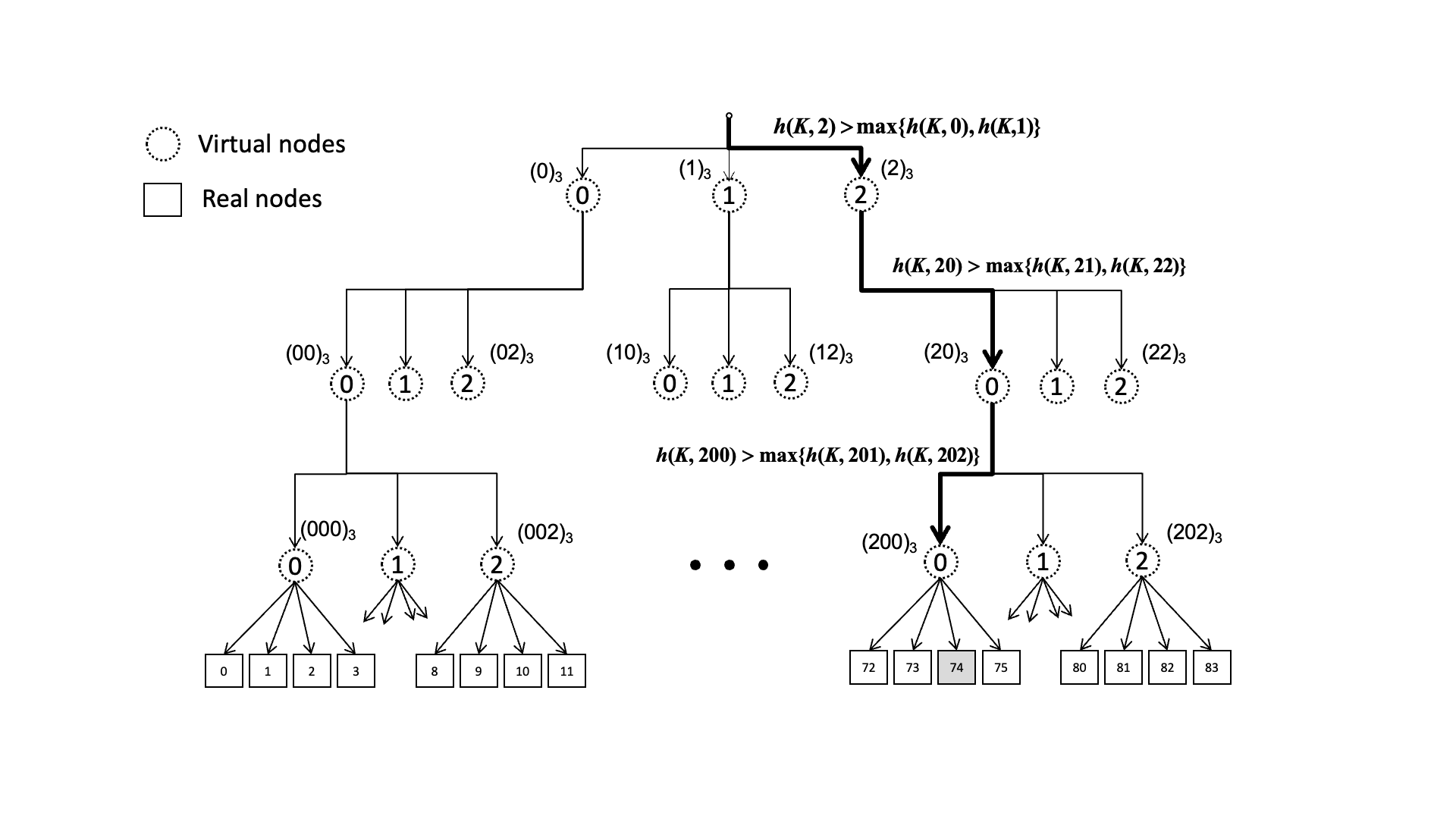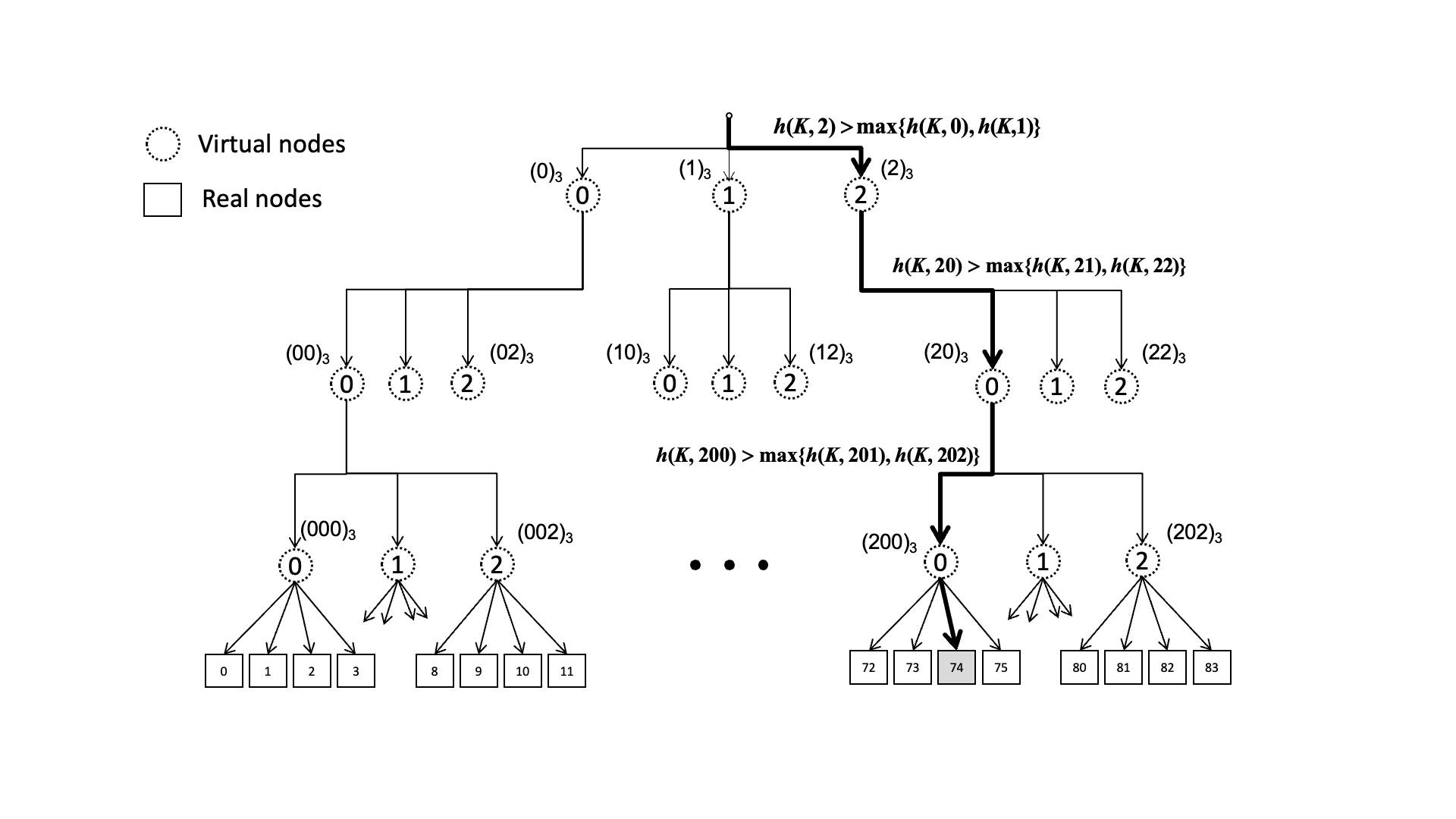
「扩展思考」
借鉴Rendezvous哈希的思想,但是又不想对每一个RS都单独计算一遍,对每个 RS 都计算哈希并排序的时间开销较高。当时就想到说是不是可以改为直接以 key 哈希后进行切分,每 MAX_RS_NUM (1024 10bits) 为一组,顺序判断对应的 RS 是否存在并存活,维护 RS 数组且在删除时不向前移动补齐。或是提供第二种哈希算法作为备选
目的:提供第二选择,而非在 rs_buf 中顺序的向后查找
这其实就是 DxHash 算法的根本思想
Locality Sensitive 哈希 (LSH)
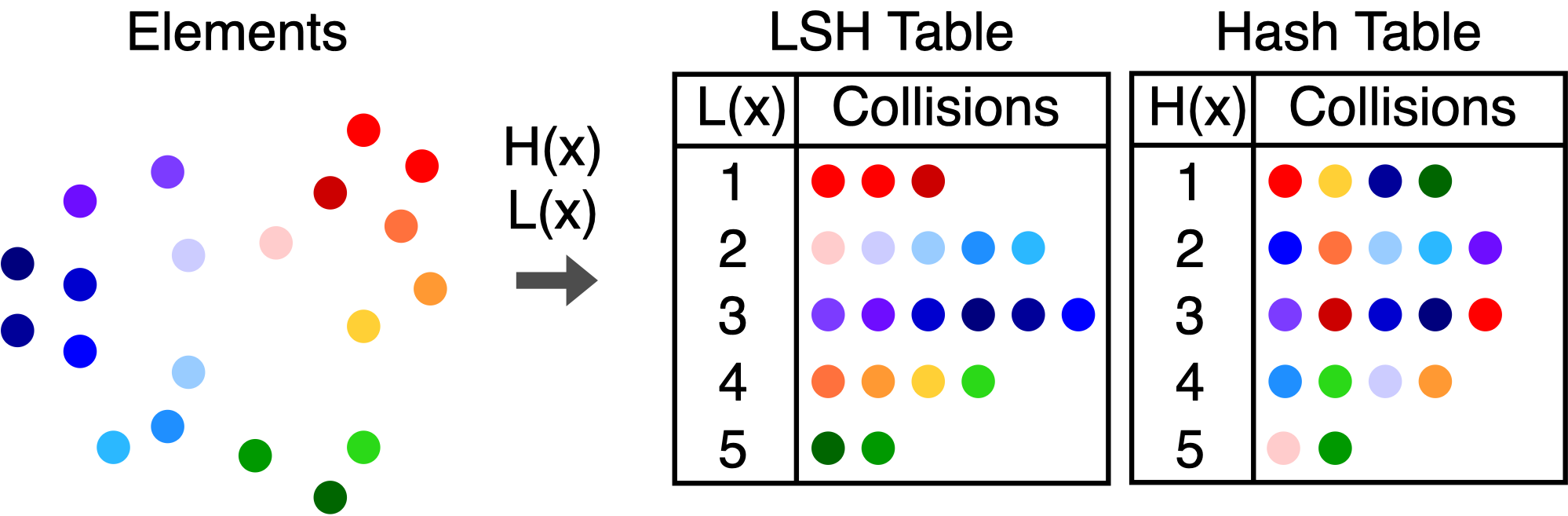
「进阶」
Multi-Probe LSH
核心思想是使用一个严格挑选的探测序列来检测多个可能包含最近邻点的桶,增大找到近邻点的概率。实验证明,在保证相同时间效率的情况下,减少了一个数量级的哈希表数量;在保证相同的搜索质量的情况下,减少了查询时间,同时少用了 5-8 倍的哈希表。
「扩展思考」
LSH 在这里引入是因为它会将相似的 key 更有可能计算出相同的哈希结果(即发生哈希碰撞),在以地理位置等进行划分的场景下可能会有用,这里不做详细介绍
产品实现
- 美团 MGW
- 哈希环 srcIP
- 爱奇艺 DPVS
- Nginx (L7)
- Bilibili (L7)
- Cloudflare Unimog
- GitHub GLB
- Google Maglev
- Aliyun
- RR
- WRR
- W-minConn
- CHash (srcIP, 4-tuple, QUIC ID)
只有 CHash 算法本身提供了会话保持能力
虽然 NLB 和 CLB 支持 QUIC ID 哈希,但仅支持 Q10、Q29 版本
- Huawei
- WRR
- W-minConn
- CHash (srcIP, QUIC ID)
支持全调度算法的会话保持
Bilibili
b站这篇后来发现实际上是7层的LB,所以很多实现方式上不太一样,但是比较有意思,所以这里作为开拓思路的一个
它一直想解决的问题是,能不能实时的去获取后方RS的当前状态,从而做出更合适的调度。在早期的实现里,它在每次请求返回里都夹带了cpu的使用率,然后每隔一段时间根据返回结果和收集到的延迟更新一次权重
但是它也遇到了SWRR中集群会做出同样的结果的问题,因为更新是滞后且不互通的
LB 1.0
- WRR
- 问题
- 无法快速摘除有问题的节点
- 无法均衡后端负载
- 无法降低总体延迟
- 问题
LB 2.0
- 动态感知的 WRR
-
方式
- 利用每次 RPC 请求返回的 Response 夹带 CPU 使用率
- 每隔一段时间整体调整一次节点的权重分数
-
问题
- 信息滞后和分布式带来的羊群效应 (VNSWRR 想解决的问题)
-
所以在3.0版本中,它们把更多因素纳入考虑,并把权重分数做成了动态的,然后又添加了随机性,来破坏羊群效应
最终他们的权重考虑了成功率、定义权重、近期的cpu使用率、时间衰减的请求延迟、当前正在处理的请求数
LB 3.0
- 带时间衰减的 Exponentially Weighted Moving Average 带系数的滑动平均值,实时更新延迟、成功率等信息,尽可能获取最新的信息
- 引入 best of two random choices 算法,加入随机性,在信息延迟较高的场景有效果
- 引入 inflight 作为参考,平衡坏节点流量,inflight 越高被调度到的机会越少
The power of two choices in randomized load balancing [Papaer]
计算权重分数
- success: 客户端成功率
- metaWeight: 在服务发现中设置的权重
- cpu: 服务端最近一段时间内的 cpu 使用率
- lag: 请求延迟
- inflight: 当前正在处理的请求数
lag 计算
// 获取&设置上次测算的时间点
stamp := atomic.SwapInt64(&pc.stamp, now)
// 获得时间间隔
td := now - stamp
// 获得时间衰减系数
w := math.Exp(float64(-td) / float64(tau))
// 获得延迟
lag := now - start
oldLag := atomic.LoadUint64(&pc.lag)
// 计算出平均延迟
lag = int64(float64(oldLag) * w + float64(lag) * (1.0 - w))
atomic.StoreUint64(&pc.lag, uint64(lag))best of two 算法
a := rand.Intn(len(p.conns))
b := rand.Intn(len(p.conns) - 1)
if b >= a {
b = b + 1
}
nodeA := p.conns[a]
nodeB := p.conns[b]
if nodeA.load() * nodeB.health() * nodeB.Weight > nodeB.load() * nodeA.health() * nodeA.Weight {
pick_node = nodeB
} else {
pick_node = nodeA
}Nginx
- WRR 默认和兜底,其他调度算法一直尝试失败会改为默认算法
nginx/src/http/ngx_http_upstream_round_robin.c : ngx_http_upstream_get_peer
- least-connect (W-minConn)
nginx/src/http/modules/ngx_http_upstream_least_conn_module.c : ngx_http_upstream_get_least_conn_peer
- W-ip-hash (srcIP)
nginx/src/http/modules/ngx_http_upstream_ip_hash_module.c : ngx_http_upstream_get_ip_hash_peer
- W-chash 哈希环
nginx/src/http/modules/ngx_http_upstream_hash_module.c : ngx_http_upstream_update_chash
- random
nginx/src/http/modules/ngx_http_upstream_random_module.c : ngx_http_upstream_peek_random_peer
- Fair Queueing 公平队列:根据后端节点服务器的响应时间来分配请求
注意,文档中说只有 ip-hash 有会话保持
「W-chash」
- 哈希桶实现。创建了 weight * 160 个影子节点,根据哈希值排序
「ip-hash」
- 对 IP 地址哈希后取模 RS 总权重,然后依次减掉每一个 RS 的权重看落在哪个 RS 里,从而将权重作为影响因素放入直接哈希
「least-connect」
- 顺序遍历 O(N) 查找连接数最小的 RS
- 出现相同的最小连接数时,回退到 SWRR 进行选择
- 比较连接数时,因为是遍历的两两比较,可以通过
peer->conns * best->weight < best->conns * peer->weight来考虑权重
「SWRR」
这个是Nginx实现SWRR调度的源码部分。它每一轮去更新RS的当前权重,并判断出当前权重最大的节点,在最后best减去总权重
注意到total和effective weight部分的处理比较特殊。一个是它会每一次大循环遍历都累加出总权重,另一个是它的定义权重是会变化的
# nginx/src/http/ngx_http_upstream_round_robin.c : ngx_http_upstream_get_peer
for (peer = rrp->peers->peer, i = 0;
peer;
peer = peer->next, i++)
{
if (peer->down) {
continue;
}
if (peer->max_fails
&& peer->fails >= peer->max_fails
&& now - peer->checked <= peer->fail_timeout)
{
continue;
}
if (peer->max_conns && peer->conns >= peer->max_conns) {
continue;
}
peer->current_weight += peer->effective_weight;
total += peer->effective_weight;
if (peer->effective_weight < peer->weight) {
peer->effective_weight++;
}
if (best == NULL || peer->current_weight > best->current_weight) {
best = peer;
p = i;
}
}
best->current_weight -= total;
return best;- weight: 配置文件中的权重
- effective_weight: 动态的有效权重,初始化为 weight。当和 RS 通信发生错误时减小,后续逐步恢复
「扩展思考」在系统初始时,通过将所有 effective_weight 初始化为 1 来放大随机效果(选 best 时也可以添加随机数判断 peer->current_weight == best->current_weight 时是否要替换 best = peer)
但是参考 ngx_http_upstream_init_round_robin 初始化中的赋值,都会有 peer.weight = peer.effective_weight = server.weight
这是我对SWRR算法的优化尝试。随机性的引入可以像这里的随机数阈值判断,或像 DGW 一样乱序 RS 列表
peer.weight = server.weight;
peer.effective_weight = 1;
random(lb_sync_ip:tid) // different in LBs and WORKERs
for all RS {
peer->current_weight += peer->effective_weight;
total += peer->effective_weight;
if (peer.effective_weight < peer.weight) {
peer.effective_weight++;
}
if (best == NULL
|| peer->current_weight > best->current_weight
|| (peer->current_weight == best->current_weight && random.next() > THRESHOLD))
{
best = peer;
}
}
best->current_weight -= total;
return best;我们将effective weight初始化为1,weight初始化为定义值。然后引入随机数来判断,当比较的两个RS当前权重相等时,只有随机结果超过阈值才会更新best,从而打乱调度顺序。其他部分仿照Nginx,逐步更新effective weight和更新best的当前权重值
我们以三台服务器为例,他们的配置权重分别为2,3,4
(number)表示在这个过程中的总权重变化,在没有达到配置权重以前它是在持续增长的;[number]代表我们随机选中的最大当前权重的节点。这里先暂时不考虑随机因素
| Server | eff | cur | eff | cur | cur | eff | cur | cur | eff | cur | cur |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A(2) | 1 | [1] | 2 | -2 | 0 | 2 | 0 | 2 | 2 | 2 | [4] |
| B(3) | 1 | 1 | 2 | 1 | [3] | 3 | -3 | 0 | 3 | 0 | 3 |
| C(4) | 1 | 1 | 2 | 1 | 3 | 3 | 3 | [6] | 4 | -2 | 2 |
| total | (3) | (6) | (8) | (9) |
Select: A B C, before current weight 4 3 2
可以看到,在权重增长的过程中,可以很有效的打乱和均分初期的调度结果。这也就是VNSWRR想要解决的羊群效应的问题,集群内的单机和单机内的WORKER在初期都会做出不同的选择
当权重增长到配置权重后,就可以像正常的SWRR一样的运行了
| Server | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A(2) | [4] | -5 | -3 | -3 | -1 | -1 | 1 | 1 | 3 | 3 | [5] | -4 | -2 | -2 | 0 | 0 | 2 | 2 | [4] |
| B(3) | 3 | 3 | [6] | -3 | 0 | 0 | 3 | 3 | [6] | -3 | 0 | 0 | 3 | 3 | [6] | -3 | 0 | 0 | 3 |
| C(4) | 2 | 2 | 6 | 6 | [10] | 1 | [5] | -4 | 0 | 0 | 4 | 4 | [8] | -1 | 3 | 3 | [7] | -2 | 2 |
Select: A B C C B A C B C
最终完整的调度顺序也是比较理想的
这个SWRR方案的好处是实现逻辑简单、解决了集群内统一调度的问题,并且可以尝试直接替换进VNSWRR的预计算的O(1)调度
爱奇艺 DPVS
DPVS源码我直接跳进了所有调度器的调度实现部分
- rr
dpvs/src/ipvs/ip_vs_rr.c - wrr
dpvs/src/ipvs/ip_vs_wrr.c实现没有平滑处理 - wlc
dpvs/src/ipvs/ip_vs_wlc.cweighted least connection- 计算所有 RS 的负载情况
(dest overhead) / dest->weight它的权重就是直接除,权重越高,计算出的负载越低,调度机会越多 dest overhead = dest->actconns << 8 + dest->inactconns负载通过移位加的方式保证先考虑当前活跃的连接数,然后再额外考虑已经关闭的连接数
- 计算所有 RS 的负载情况
- conhash(带权重哈希环)
dpvs/src/ipvs/ip_vs_conhash.c- weight / weight_gcd * REPLICA(160)
- mh(Maglev)
dpvs/src/ipvs/ip_vs_mh.cdp_vs_mh_populate填充用不变的 offset | skip | turns (weight / gcd),变的 perm(next offset)。不需要完整的计算出permutation偏好序列dp_vs_mh_get_fallbackif selected server is unavailable, loop around the table starting from idx to find a new dest。提供了一个兜底的fallback方法(尽管这会导致调度不均匀)
Cloudflare Unimog
自研硬件服务器,SDN 架构
可以根据 RS 的负载动态调整连接数量
机房内所有机器都安装了四层 LB,路由器无论把包发给哪台都会转发到正确的 RS 上
优势:
- LB 不需要做容量规划
- 最大限度防 DDoS
- 运维架构简单,所有机器都一样
LB 之间不同步状态,连接保持方案类似 Maglev:所有 LB 自己决定,但保证对于相同的 4-tuple 会转发相同的 RS。所有 LB 都接收由控制平面统一下发的转发表,通过 4-tuple-hash 查表。转发表中每个 RS 可以设置多个 bucket(权重),RS 下线只修改对应 bucket
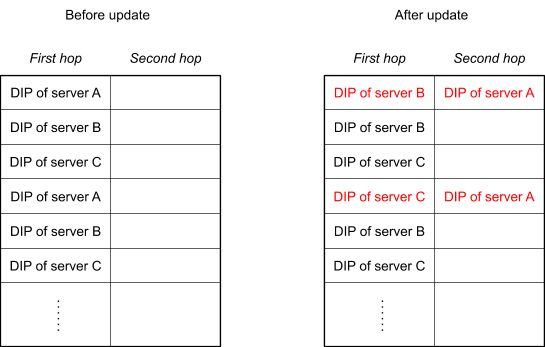
由于没有 ct,它通过备份转发表 (second hop) 方式来继续先前的转发。当一个 RS 机器收到包时,先检查当前机器有没有这个 TCP socket,如果没有就转发到 second hop
关于备份转发表存多久的问题,文章作者 kawabangga 问了 cf,解释是:
- 删除实例在 Cloudflare 不太常见,更常见的是短暂移除,reboot,然后回到集群,几乎所有的机器每月都会重启一次,所以每一个连接在 24 小时之内都有 1/30 的几率被 reset
- 如果要移除的话,如文中所说,会进入到 drain state,在备表中,这个状态只会维持几分钟
- 简单来说,连接可以归为两类:short-lived 和 long-lived。几分钟足够所有 short-lived 连接结束了,剩下的都是 long-lived,如果 drain 状态 30min,可能会有部分连接正常结束,但是不会很多,大部分超过几分钟的连接会存在数小时甚至数天,继续等待也不会带来更多显著受益,但是会让操作效率大大降低,所以只等待几分钟
GitHub GLB
GitHub有点像是软件实现的cf LB,它也会计算出主备RS。因为并非像cf那样所有机器都是LB,它需要在转发的包里记录备RS的地址告诉他可以向哪里转发
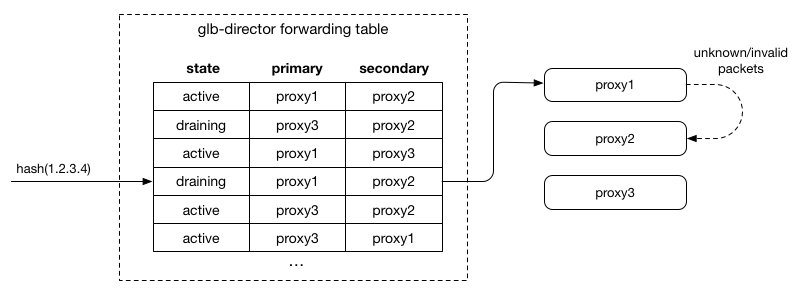
「转发过程」
- 根据 hash 查找转发表,找到对应的 2 个 RS,一个是主 RS 一个是备 RS,然后转发到主 RS
- 主 RS 收到包之后,检查这个包是不是属于自己机器上的连接,如果是,就交给协议栈处理,如果不是,就转发到备 RS(备 RS 的地址记录在 GLB 发过来的包中)
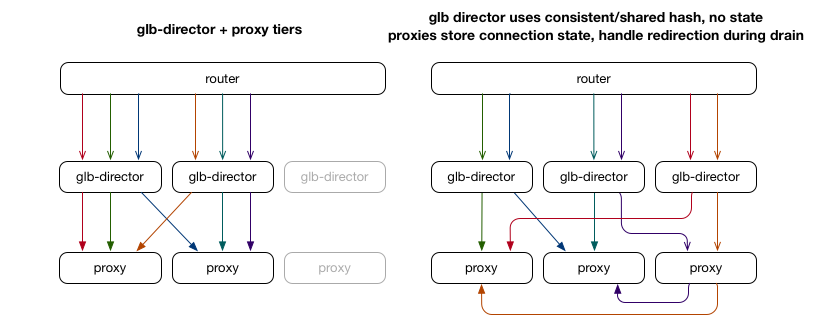
「转发表」
- 在 RS 修改的时候,只有变化的 RS 在表中会修改,没有变化的 RS 在表中的位置不变。即不能对整个表完全重新 hash
- 表的生成不依赖外部的状态
- 每一行的两个 RS 不应该相同
- 所有 RS 在表中出现的次数应该是大致相同的(负载均衡)
实现方式是类似 Rendezvous hashing:对于每一行,将行号 + RS IP 进行 Hash 得到一个数字,作为“分数”,所有的 RS 在这一行按照分数排序,取前两名,作为主 RS 和 备 RS 放到表中。然后按照以下的四个条件来分析:
- 如果添加 RS,那么只有新 RS 排名第一的相关的行需要修改,其他的行不会改变
- 生成这个表只会依赖 RS 的 IP
- 每一行的两个 RS 不可能相同,因为取的前两名
- Hash 算法可以保证每一个 IP 当第一名的概率是几乎一样的
不过要注意的是:在想要删除 RS 的时候,要交换主 RS 和 备 RS 的位置,这样,主 RS 换到备就不会有新连接了,等残留的连接都结束,就可以下线了;在添加 RS 的时候,每次只能添加一个,因为如果一次添加两个,那么这两个 RS 如果出现在同一行的第一名和第二名,之前的 RS 就会没来得及 drain 就没了,那么之前的 RS 的连接都会断掉
优势:
- 提供第二选择
- 不需要保存数据
- GLB 实例可以和 RS 同时做变化
问题:
- 要动 RS
Google Maglev
DSR 转发模式,Maglev 不会做 NAT,通过 GRE 将二层包封装进 IP 包里(需要 MSS 预留空间)
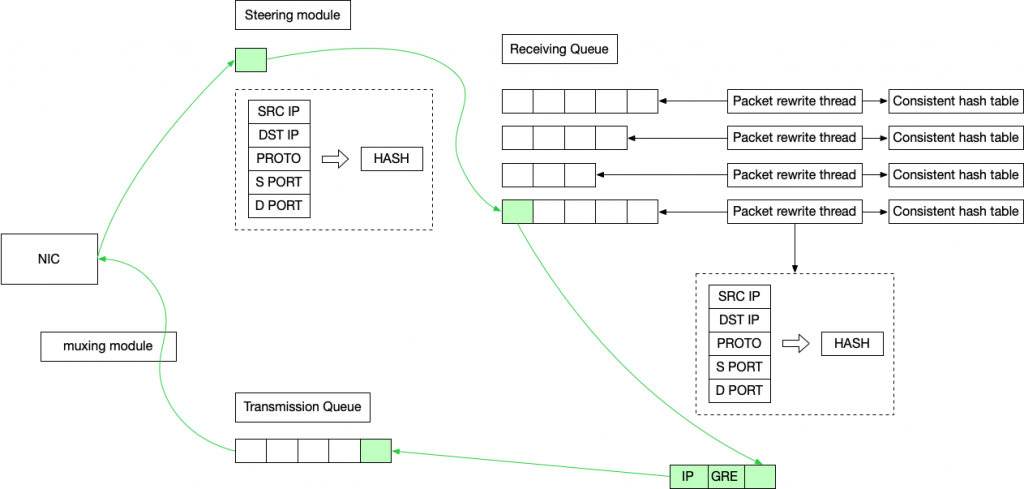
上图是包的转发流程,绿色的是包经过的路径
Reference
部分参考
- 一致性哈希算法 - 问题的提出 - 哈希环法 - 跳跃一致性哈希法 - Maglev 一致性哈希法
- Consistent Hashing: Algorithmic Tradeoffs 一致性哈希:算法权衡 和 libchash
- 一致性哈希汇总
- ketama (源码)
- Jump Consistent Hash 算法
- A Fast, Minimal Memory, Consistent Hash Algorithm (论文)
- Multi-Probe Consistent Hashing (论文)
- Maglev: A Fast and Reliable Software Network Load Balancer (论文)
- AnchorHash: A Scalable Consistent Hash (论文)
- AnchorHash (源码)
- DxHash: A Scalable Consistent Hashing Based on the Pseudo-Random Sequence (论文)
- Rendezvous hashing 算法介绍
- Rendezvous Hashing Explained (原文)
- Rendezvous Hashing 源码和实验对比
- Rendezvous Hashing 基于骨架的分层会合散列 O(logN) 优化
- LSH 位置敏感哈希入门
- Consistently Faster: A survey and fair comparison of consistent hashing algorithms
- 四层负载均衡漫谈
- 「Bilibili」RPC 负载均衡算法的演进之路
- 「美团」MGW——美团点评高性能四层负载均衡
- 「华为云」配置会话保持提升访问效率
- 「阿里云」负载均衡调度算法介绍
- 「Nginx」Nginx 源码 和 Nginx SWRR Commit
- 「LVS」LVS WRR
- 「爱奇艺」DPVS (源码)
- 「Cloudflare」Unimog - Cloudflare’s edge load balancer
- 「GitHub」GLB: GitHub’s open source load balancer 和 GLB 源码
- 「Google」四层负载均衡分析:Google Maglev